

Authors:
(1) An Yan, UC San Diego, [email protected];
(2) Zhengyuan Yang, Microsoft Corporation, [email protected] with equal contributions;
(3) Wanrong Zhu, UC Santa Barbara, [email protected];
(4) Kevin Lin, Microsoft Corporation, [email protected];
(5) Linjie Li, Microsoft Corporation, [email protected];
(6) Jianfeng Wang, Microsoft Corporation, [email protected];
(7) Jianwei Yang, Microsoft Corporation, [email protected];
(8) Yiwu Zhong, University of Wisconsin-Madison, [email protected];
(9) Julian McAuley, UC San Diego, [email protected];
(10) Jianfeng Gao, Microsoft Corporation, [email protected];
(11) Zicheng Liu, Microsoft Corporation, [email protected];
(12) Lijuan Wang, Microsoft Corporation, [email protected].
Editor’s note: This is the part 9 of 13 of a paper evaluating the use of a generative AI to navigate smartphones. You can read the rest of the paper via the table of links below.
Table of Links
- Abstract and 1 Introduction
- 2 Related Work
- 3 MM-Navigator
- 3.1 Problem Formulation and 3.2 Screen Grounding and Navigation via Set of Mark
- 3.3 History Generation via Multimodal Self Summarization
- 4 iOS Screen Navigation Experiment
- 4.1 Experimental Setup
- 4.2 Intended Action Description
- 4.3 Localized Action Execution and 4.4 The Current State with GPT-4V
- 5 Android Screen Navigation Experiment
- 5.1 Experimental Setup
- 5.2 Performance Comparison
- 5.3 Ablation Studies
- 5.4 Error Analysis
- 6 Discussion
- 7 Conclusion and References
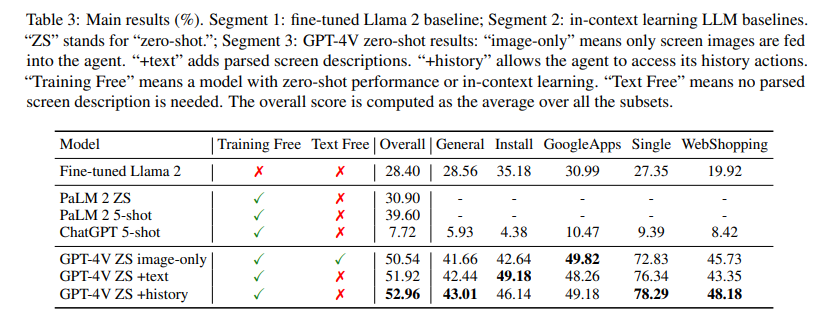
5.2 Performance Comparison
Our main results are shown in Table 3. First, GPT4V outperforms previous LLMs that take groundtruth descriptions of the screens as inputs. Compared with previous text-only LLMs, taking screen images as visual inputs provides an easier way for human-model interactions. It also better preserves the screen information and avoids the information loss when converting screens to text descriptions. Additionally, adding screen descriptions still improves the performance of GPT-4V. Giving the agent access to its historical interactions is helpful for better conditioned and grounded generation, and our in-context self-summarization module provides an efficient way to achieve this. Overall, we find GPT-4V presents a strong level of screen understanding of icons and text, showing the potential of visual-based device control with LMMs.
This paper is available on arxiv under CC BY 4.0 DEED license.