
What Happens When Your Prompt Is Too Obscure?
10 Jul 2025
New research shows how T2I models like Stable Diffusion struggle with rare prompts, revealing key accuracy gaps across head and tail concepts.

A Close Look at Misalignment in Pretraining Datasets
10 Jul 2025
Why RAM++ beats CLIP for fine-grained image concept detection, with a focus on threshold tuning and identifying misaligned image-text pairs.
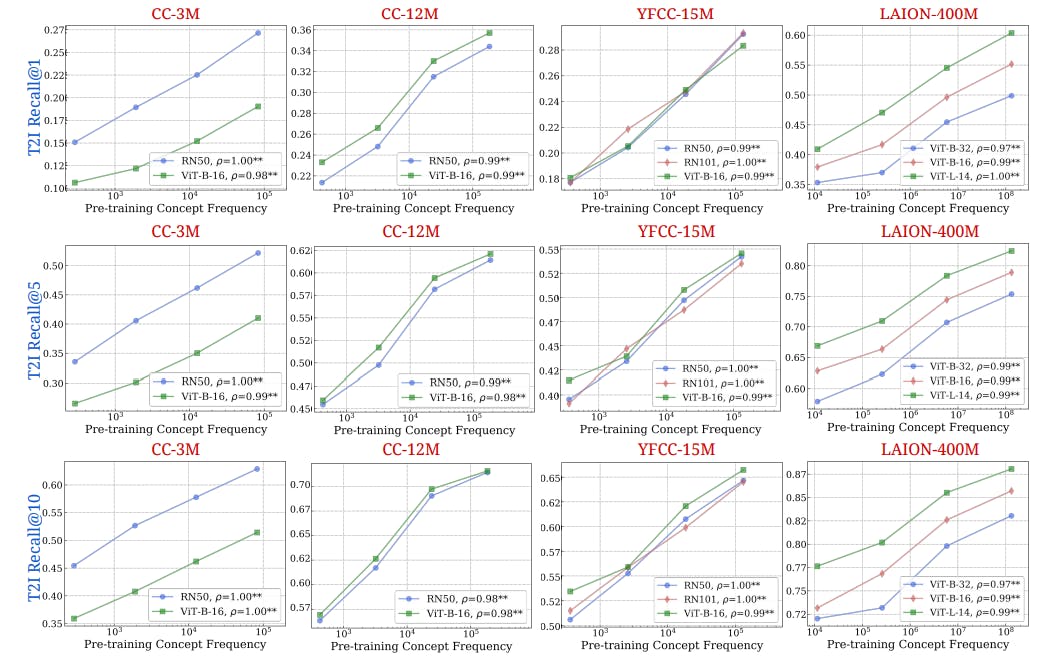
The Link Between Concept Frequency and AI Performance, Seen Through Images and Words
10 Jul 2025
Concept frequency improves zero-shot AI performance across image and text domains, confirmed through detailed dataset analysis and cleaning methods.
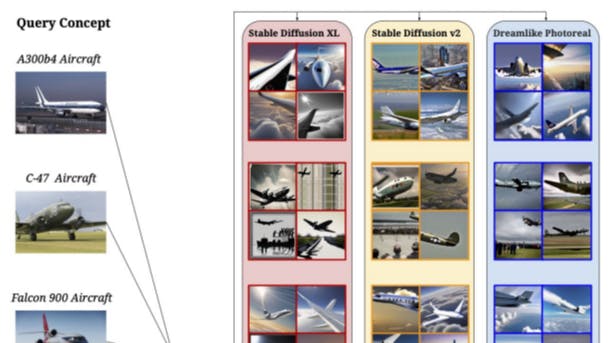
How Concept Frequency Affects AI Image Accuracy
9 Jul 2025
Concept frequency in training data predicts zero-shot accuracy in T2I models like Stable Diffusion, especially when generating images of public figures.
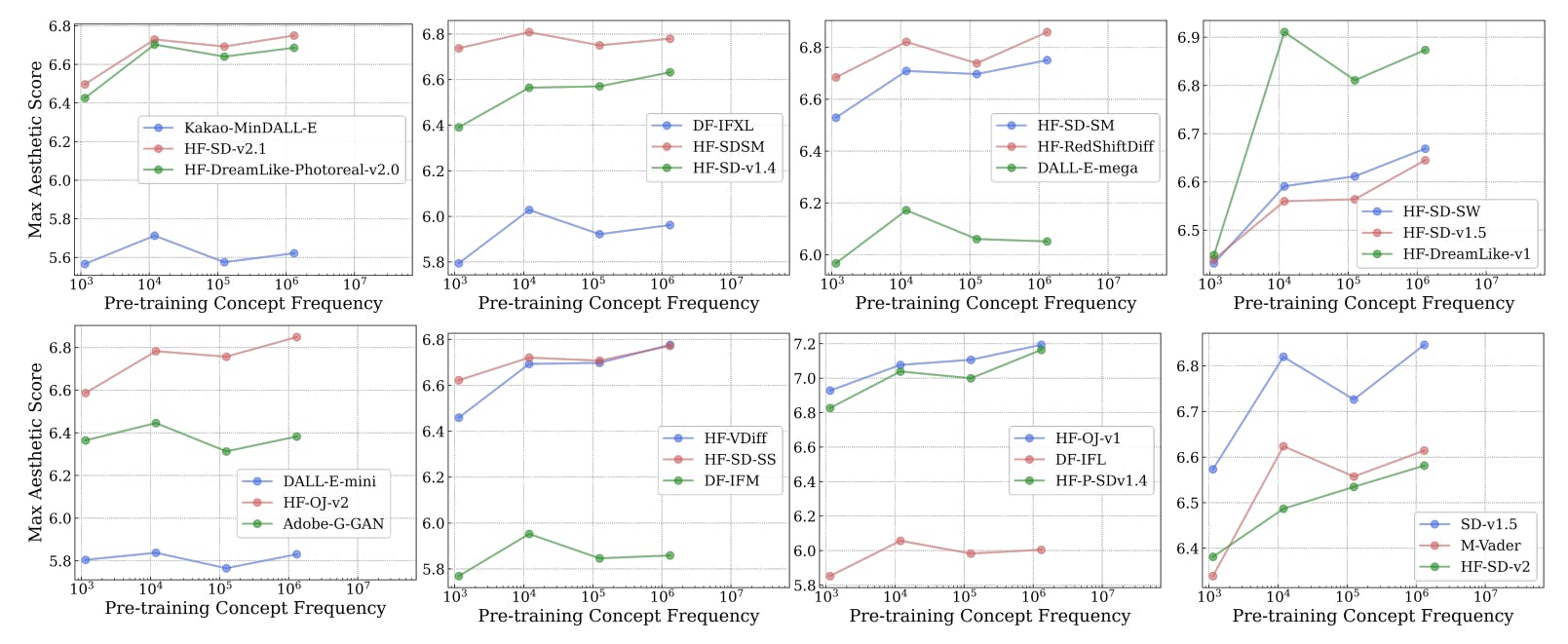
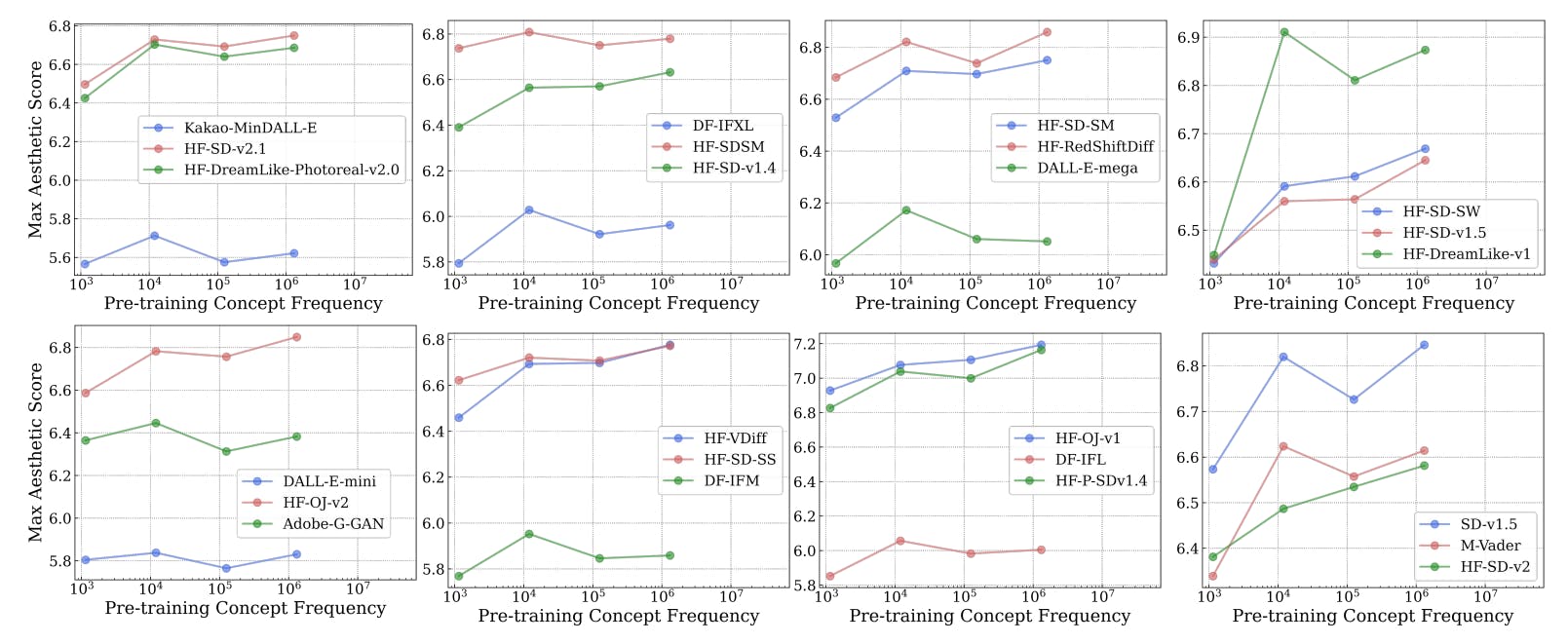
Across Metrics and Prompts, Frequent Concepts Outperform in Zero-Shot Learning
9 Jul 2025
Concept frequency strongly predicts zero-shot AI performance across multiple prompting styles and six retrieval metrics, study confirms.
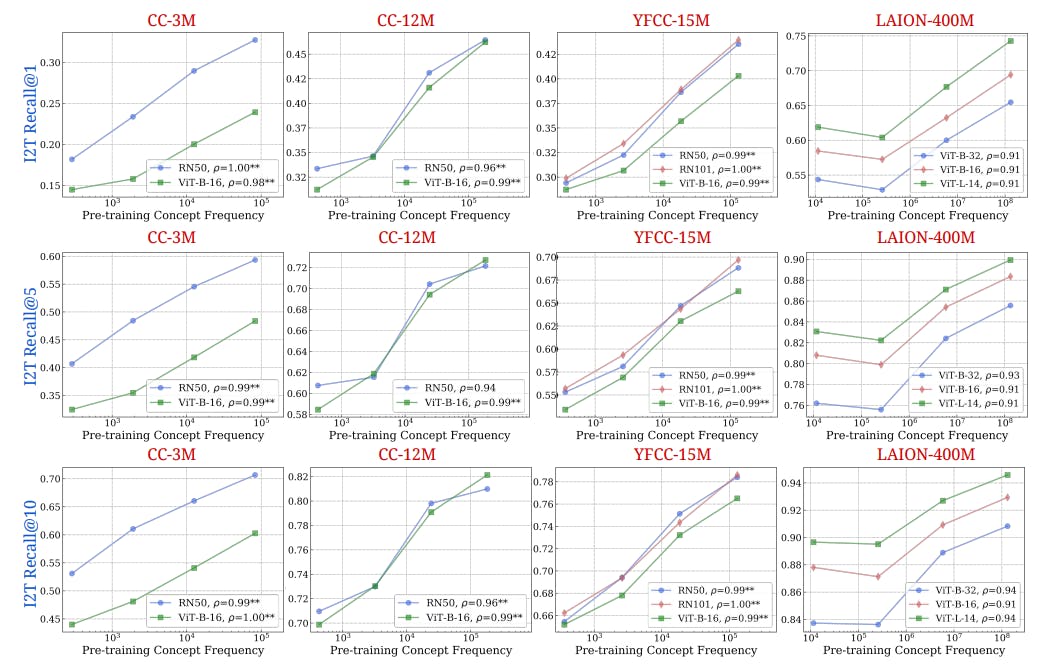
What 34 Vision-Language Models Reveal About Multimodal Generalization
9 Jul 2025
Multimodal models struggle with long-tail concepts. This study analyzes 34 models and 300GB of data to reveal key limitations in zero-shot generalization.
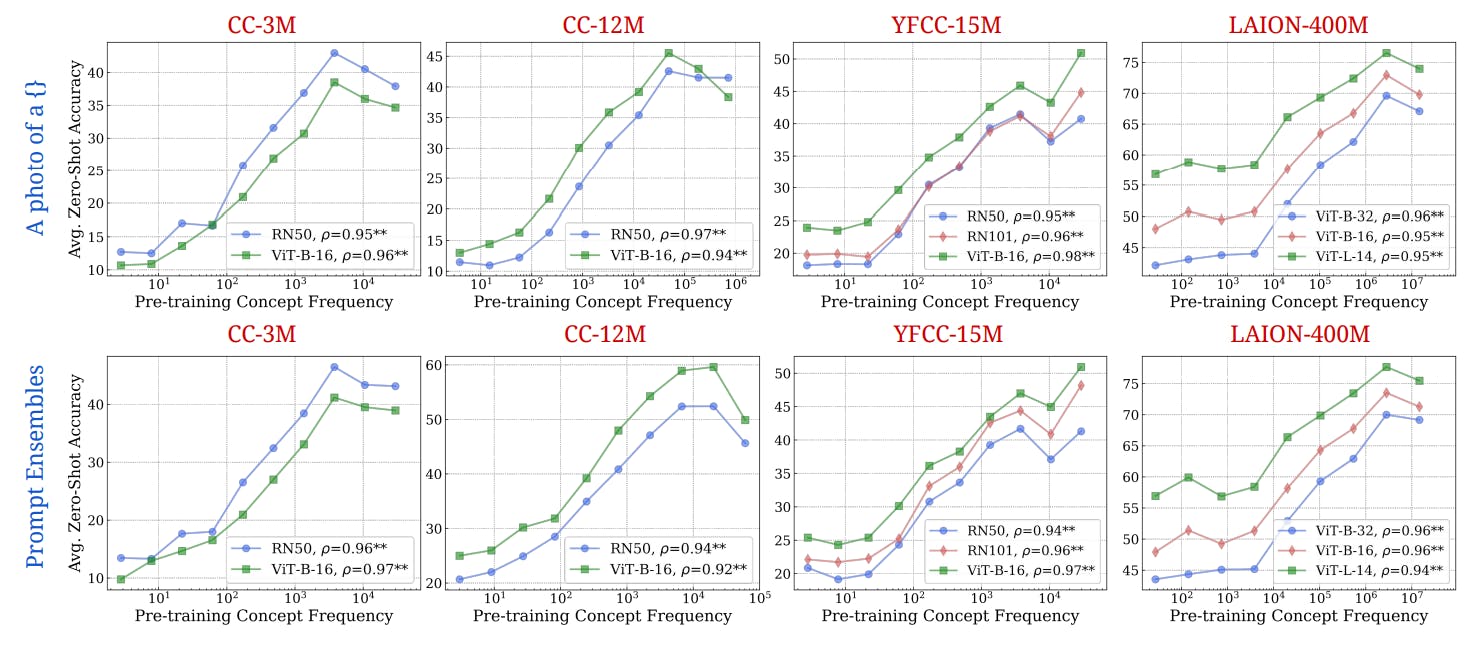
How Dataset Diversity Impacts AI Model Performance
9 Jul 2025
Long-tailed data in large-scale AI datasets affects model performance. This article analyzes the root causes and implications for future model training.
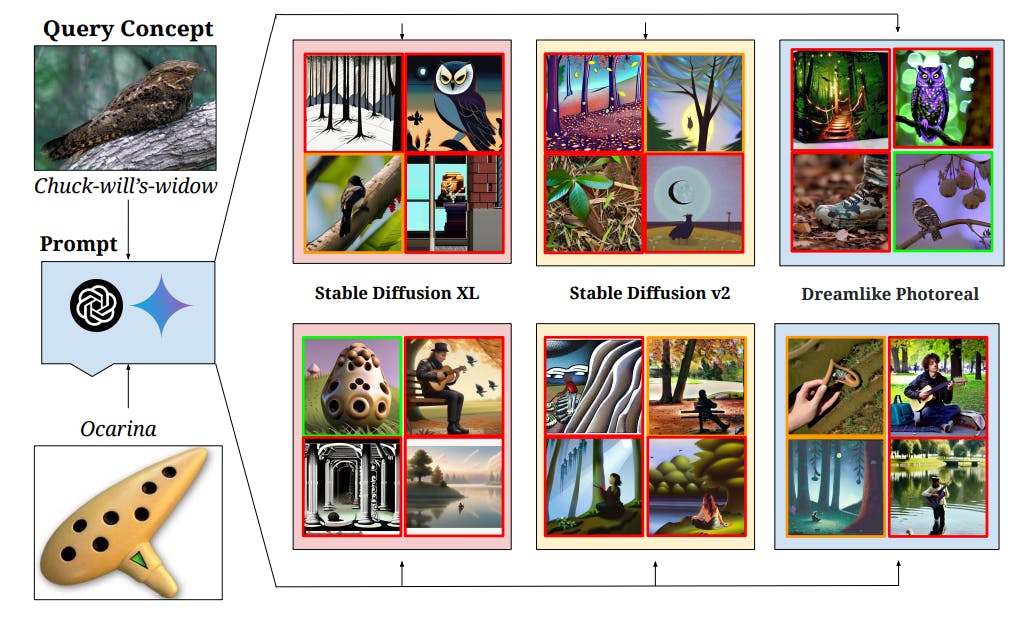
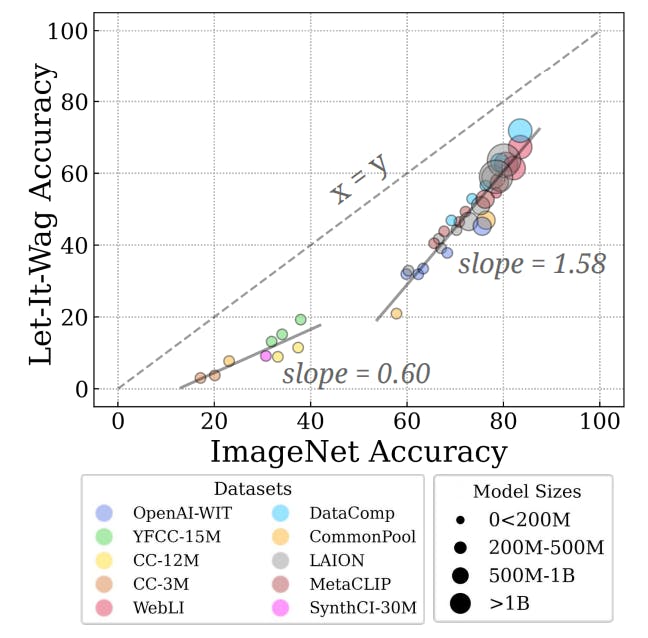
‘Let It Wag!’ and the Limits of Machine Learning on Rare Concepts
8 Jul 2025
New study reveals why AI models underperform on rare concepts using the “Let It Wag!” dataset of long-tail categories in classification and generation tasks.
AI Training Data Has a Long-Tail Problem
8 Jul 2025
New findings reveal long-tailed distributions, image-text misalignment, and consistent concept patterns across major AI pretraining datasets.