

Table of Links
4 Results and 4.1 Increasing number of demonstrating examples
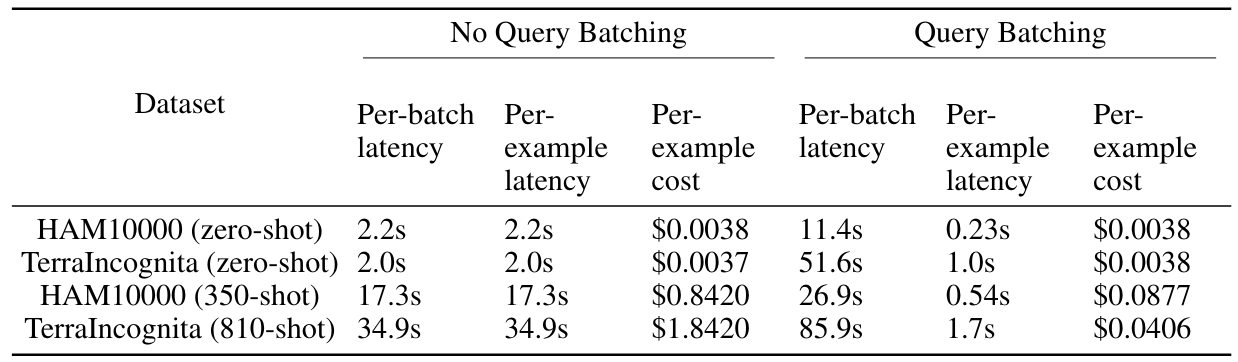
4.2 Impact of batching queries
A. Prompts used for ICL experiments
C. GPT4(V)-Turbo performance under many-shot ICL
D. Performance of many-shot ICL on medical QA tasks
Acknowledgments and Disclosure of Funding
5 Discussion
In this study, we evaluate many-shot ICL of state-of-the-art multimodal foundation models across 10 datasets and find consistent performance improvements across most of the datasets. Batching queries with many-shot ICL further exhibits substantially reduced per-example latency and inference costs without compromising performance.
Our findings suggest that these multimodal foundation models have the capability of performing ICL with large numbers of demonstrating examples, which may have significant implications on their practical use. For example, it was previously impossible to adapt these large, private models to
new tasks and domains, but many-shot ICL would enable users to leverage demonstrating examples to adapt the models. One significant advantage of many-shot ICL is its ability to get quick results even on the same day of model release, and that’s why we can finish our evaluation using GPT-4o within days. Furthermore, fine-tuning open-source models is the standard practice when practitioners have access to moderately sized datasets, but many-shot ICL may remove the need for fine-tuning, making it much easier to develop customized approaches. We note that it remains to be seen how traditional fine-tuning of these models compares to many-shot ICL with foundation models in terms of absolute performance and data efficiency, so future work should explore this. In addition, it is important to study general issues which plague those foundation models, such as hallucinations and biases, under the context of many-shot ICL and batching queries. For example, it would be interesting to explore if carefully curated and large sets of demonstrating examples can reduce biases across different sub-groups. We leave this to future work.
Our study has limitations. First, we only explore performance under many-shot ICL on image classification tasks and with private foundation models. We believe these are the most practically relevant and common multimodal settings, but it is worthwhile for future work to explore potential benefits from many-shot ICL on other tasks and with upcoming open-source multimodal foundation models like LLaMA-3 [30]. Second, even after recent developments to increase context size, the size prohibits many-shot ICL from being used on datasets with a large number (several hundred or more) of classes. We anticipate that context window sizes will continue to increase in size over time which will mitigate this issue. Third, the datasets which were used to train these private models have not been disclosed, so it is difficult to tell whether the models have been trained on the datasets we selected. We argue that zero-shot performance across the datasets is far from perfect which provides evidence that the datasets have not been used for training, but we cannot determine that with certainty.
6 Conclusion
In summary, we show that multimodal foundation models are capable of many-shot ICL. We believe that these results pave a promising path forward to improve the adaptability and accessibility of large multimodal foundation models.
References
[1] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners, 2020.
[2] Archit Parnami and Minwoo Lee. Learning from few examples: A summary of approaches to few-shot learning. arXiv preprint arXiv:2203.04291, 2022.
[3] Yaqing Wang, Quanming Yao, James T Kwok, and Lionel M Ni. Generalizing from a few examples: A survey on few-shot learning. ACM computing surveys (csur), 53(3):1–34, 2020.
[4] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[5] Zhongyi Han, Guanglin Zhou, Rundong He, Jindong Wang, Xing Xie, Tailin Wu, Yilong Yin, Salman Khan, Lina Yao, Tongliang Liu, et al. How well does gpt-4v (ision) adapt to distribution shifts? a preliminary investigation. arXiv preprint arXiv:2312.07424, 2023.
[6] Xingxuan Zhang, Jiansheng Li, Wenjing Chu, Junjia Hai, Renzhe Xu, Yuqing Yang, Shikai Guan, Jiazheng Xu, and Peng Cui. On the out-of-distribution generalization of multimodal large language models. arXiv preprint arXiv:2402.06599, 2024.
[7] Mukai Li, Shansan Gong, Jiangtao Feng, Yiheng Xu, Jun Zhang, Zhiyong Wu, and Lingpeng Kong. In-context learning with many demonstration examples. arXiv preprint arXiv:2302.04931, 2023.
[8] Rishabh Agarwal, Avi Singh, Lei M Zhang, Bernd Bohnet, Stephanie Chan, Ankesh Anand, Zaheer Abbas, Azade Nova, John D Co-Reyes, Eric Chu, et al. Many-shot in-context learning. arXiv preprint arXiv:2404.11018, 2024.
[9] Amanda Bertsch, Maor Ivgi, Uri Alon, Jonathan Berant, Matthew R Gormley, and Graham Neubig. In-context learning with long-context models: An in-depth exploration. arXiv preprint arXiv:2405.00200, 2024.
[10] Haozhe Zhao, Zefan Cai, Shuzheng Si, Xiaojian Ma, Kaikai An, Liang Chen, Zixuan Liu, Sheng Wang, Wenjuan Han, and Baobao Chang. Mmicl: Empowering vision-language model with multi-modal in-context learning. arXiv preprint arXiv:2309.07915, 2023.
[11] Zhoujun Cheng, Jungo Kasai, and Tao Yu. Batch prompting: Efficient inference with large language model apis. arXiv preprint arXiv:2301.08721, 2023.
[12] Jianzhe Lin, Maurice Diesendruck, Liang Du, and Robin Abraham. Batchprompt: Accomplish more with less. arXiv preprint arXiv:2309.00384, 2023.
[13] Jiayi Liu, Tinghan Yang, and Jennifer Neville. Cliqueparcel: An approach for batching llm prompts that jointly optimizes efficiency and faithfulness. arXiv preprint arXiv:2402.14833, 2024.
[14] Guijin Son, Sangwon Baek, Sangdae Nam, Ilgyun Jeong, and Seungone Kim. Multi-task inference: Can large language models follow multiple instructions at once? arXiv preprint arXiv:2402.11597, 2024.
[15] Siyu Xu, Yunke Wang, Daochang Liu, and Chang Xu. Collage prompting: Budget-friendly visual recognition with gpt-4v. arXiv preprint arXiv:2403.11468, 2024.
[16] Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jeanbaptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
[17] Yixuan Wu, Yizhou Wang, Shixiang Tang, Wenhao Wu, Tong He, Wanli Ouyang, Jian Wu, and Philip Torr. Dettoolchain: A new prompting paradigm to unleash detection ability of mllm. arXiv preprint arXiv:2403.12488, 2024.
[18] Yuhang Zang, Wei Li, Jun Han, Kaiyang Zhou, and Chen Change Loy. Contextual object detection with multimodal large language models. arXiv preprint arXiv:2305.18279, 2023.
[19] Philipp Tschandl, Cliff Rosendahl, and Harald Kittler. The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific data, 5(1): 1–9, 2018.
[20] Kai Jin, Xingru Huang, Jingxing Zhou, Yunxiang Li, Yan Yan, Yibao Sun, Qianni Zhang, Yaqi Wang, and Juan Ye. Fives: A fundus image dataset for artificial intelligence based vessel segmentation. Scientific Data, 9(1):475, 2022.
[21] Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 590–597, 2019.
[22] Peter Bandi, Oscar Geessink, Quirine Manson, Marcory Van Dijk, Maschenka Balkenhol, Meyke Hermsen, Babak Ehteshami Bejnordi, Byungjae Lee, Kyunghyun Paeng, Aoxiao Zhong, et al. From detection of individual metastases to classification of lymph node status at the patient level: the camelyon17 challenge. IEEE transactions on medical imaging, 38(2):550–560, 2018.
[23] Sara Beery, Grant Van Horn, and Pietro Perona. Recognition in terra incognita. In Proceedings of the European conference on computer vision (ECCV), pages 456–473, 2018.
[24] Yi Yang and Shawn Newsam. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL international conference on advances in geographic information systems, pages 270–279, 2010.
[25] Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019.
[26] Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In 2012 IEEE conference on computer vision and pattern recognition, pages 3498–3505. IEEE, 2012.
[27] Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014.
[28] Yuanfeng Ji, Lu Zhang, Jiaxiang Wu, Bingzhe Wu, Long-Kai Huang, Tingyang Xu, Yu Rong, Lanqing Li, Jie Ren, Ding Xue, et al. Drugood: Out-of-distribution (ood) dataset curator and benchmark for ai-aided drug discovery–a focus on affinity prediction problems with noise annotations. arXiv preprint arXiv:2201.09637, 2022.
[29] Wei-Lin Chen, Cheng-Kuang Wu, and Hsin-Hsi Chen. Self-icl: Zero-shot in-context learning with self-generated demonstrations. arXiv preprint arXiv:2305.15035, 2023.
[30] Introducing meta llama 3: The most capable openly available llm to date. URL https: //ai.meta.com/blog/meta-llama-3/.
Authors:
(1) Yixing Jiang, Stanford University ([email protected]);
(2) Jeremy Irvin, Stanford University ([email protected]);
(3) Ji Hun Wang, Stanford University ([email protected]);
(4) Muhammad Ahmed Chaudhry, Stanford University ([email protected]);
(5) Jonathan H. Chen, Stanford University ([email protected]);
(6) Andrew Y. Ng, Stanford University ([email protected]).
This paper is