

Table of Links
4 Results and 4.1 Increasing number of demonstrating examples
4.2 Impact of batching queries
A. Prompts used for ICL experiments
C. GPT4(V)-Turbo performance under many-shot ICL
D. Performance of many-shot ICL on medical QA tasks
Acknowledgments and Disclosure of Funding
4 Results
We present many-shot ICL performance using batched queries in Section 4.1, investigate the impact of batching queries on performance in Section 4.2, and provide an analysis on cost and latency in Section 4.3. Results using GPT4(V)-Turbo are in Appendix C.
4.1 Increasing number of demonstrating examples
Main Results. Gemini 1.5 Pro exhibits consistent and substantial improvements as the number of demonstrating examples increases across all datasets except for DrugOOD Assay (Figure 2). Gemini 1.5 Pro shows particularly large improvements from many-shot ICL on HAM10000 (+23% accuracy compared to zero-shot, +16% compared to 7 examples), FIVES (+29% compared to zero-shot, +27% compared to 20 examples), and EuroSAT (+38% compared to zero-shot, +31% compared to 10 examples). Notably, for 5 out of the 10 datasets (FIVES, UCMerced, EuroSAT, Oxford Pets, and DTD), Gemini 1.5 Pro performance continues to improve up to the highest number of demonstrating examples considered (~1,000 examples). On the other 5 datasets, the optimal performance occurs prior to the highest number of demo examples, with the maximum number of demo examples leading to similar or slightly worse performance than the optimal demo set size. On the other hand, Gemini 1.5 Pro performance on DrugOOD Assay does not substantially benefit from many-shot ICL, with high variance in performance across demo sizes and the peak performance at 40 demo examples.
Similarly, GPT-4o shows substantial performance improvements on all datasets except FIVES and DrugOOD Assay using many-shot ICL, but the improvement is not consistent. For many datasets, performance drops sharply at first and then improves significantly as the number of demonstrating examples increases further, resulting in V-shaped scaling curves (Figure 2). We also note that we were unable to increase the number of demo examples to the same level as considered for Gemini 1.5 Pro because GPT-4o has a shorter context window and is more prone to timeout errors with longer inputs. GPT-4o performance on DrugOOD Assay shows high variance, similar to Gemini 1.5 Pro, with the peak performance observed at 50 demo examples.
Sensitivity to prompt selection. We also explore a different set of prompts to test the robustness of many-shot ICL to differences in prompt wording on two datasets. While there is a small deviation in performance between different prompts, the overall log-linear improvement trend is consistent across the prompts. Details can be found in Appendix B.
ICL data efficiency. We find Gemini 1.5 Pro demonstrates higher ICL data efficiency than GPT4o across all datasets except TerraIncognita and DTD (Table 2). Gemini 1.5 Pro ICL efficiency is especially high on EuroSAT, with 20.61% improvement in accuracy for every 10x more demo examples, and lowest on DrugOOD Assay (2.03), Camelyon17 (3.00), and TerraIncognita (3.50). GPT-4o ICL data efficiency is especially high on TerraIncognita (20.50%) and EuroSat (19.40).
Gemini 1.5 Pro has a positive efficiency on all datasets and GPT-4o has a positive data efficiency on 9 of the 10 datasets (excluding Oxford Pets). Importantly, both models benefit substantially from many-shot ICL at the optimal demo set size, with an average improvement of +17% for both Gemini 1.5 Pro and GPT-4o.
4.2 Impact of batching queries
As including a large set of demo examples in the prompt leads to much longer sequence lengths and therefore higher inference time and cost, we consider batching queries in a single prompt to reduce per-query cost, and examine the impact of different batch sizes on model performance. Due to its superior performance and free preview access, we use Gemini 1.5 Pro for these experiments.
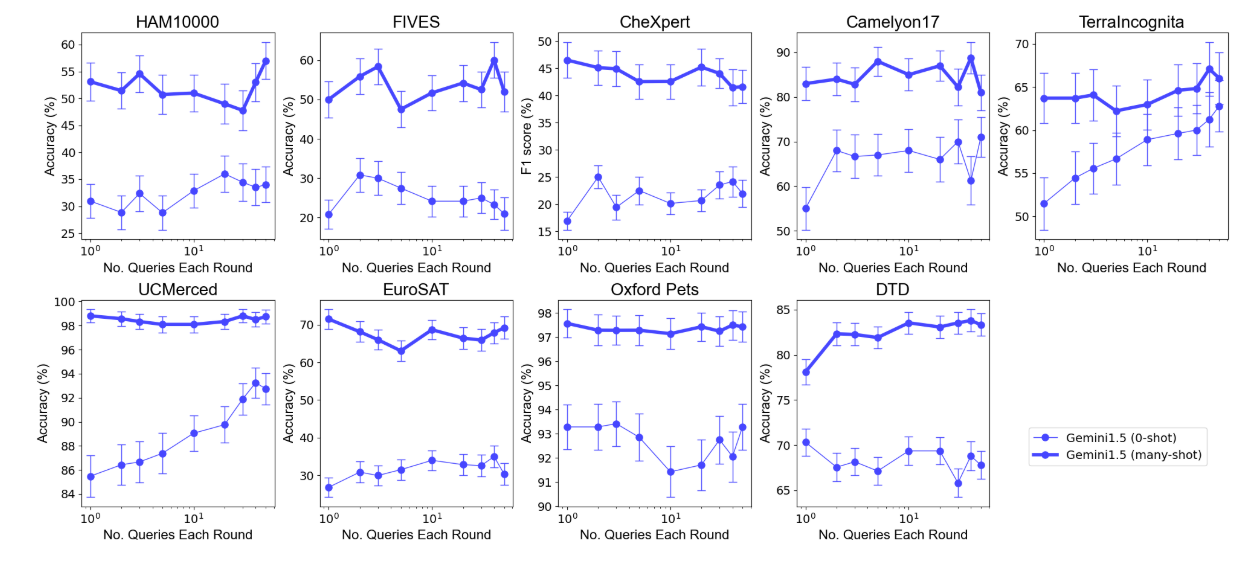
Main Results. We find minimal performance degradations, and sometimes performance improvements, as we increase the number of queries included in each batch across under both zero-shot and many-shot (at the optimal demo set size) regimes (Figure 3). Notably, using a single query each time with many-shot ICL is suboptimal across many of the datasets. We find that the optimal batch size is among the three largest sizes on every dataset except CheXpert and EuroSAT, which both see optimal performance with a single query at a time.
We additionally observe that including a single query at a time is suboptimal on most datasets in the zero-shot regime. Surprisingly, performance with the highest batch size is substantially higher across three datasets under the zero-shot regime, with a consistent performance improvement as the batch size is increased on both UCMerced and Terraincognita.
Zero-shot performance improvements from batching queries. We conduct several additional experiments to investigate why batch querying can lead to large performance improvements under the zero-shot regime on TerraIncognita and UCMerced. We hypothesize that this improvement may be due to three potential benefits from ICL: (1) domain calibration, where the model benefits from seeing more images in the domain in order to adapt to it, (2) class calibration, where seeing images of different classes enables the model to better calibrate its outputs, and (3) self-ICL (shown to be effective in prior work [29]), where the model can learn from self-generated demonstrations due to autoregressive decoding. We design experiments to isolate the potential benefits from each of these types of ICL between asking a single query to batching 50 queries together.
First, to measure potential improvement from domain calibration, we include 49 images from the same class in the prompt without including any label. We find a 3.0% improvement on TerraIncognita
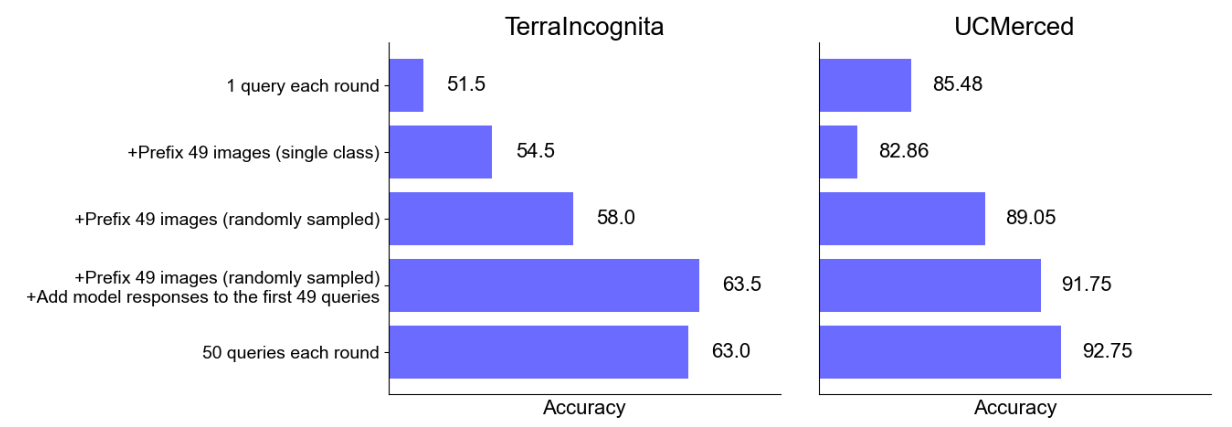
and 2.6% degradation on UCMerced, suggesting domain calibration is helpful for the former but not the latter. Second, to capture performance gains from class calibration, we include a random sample of 49 images in the prompt, again without including the label. We see a further 3.5% improvement on TerraIncognita (6.5% improvement from a single query) and a 4.5% improvement from a single query on UCMerced, suggesting including the context of class-balanced images is helpful even without labels. Third, to capture additional performance improvements from the self-generated labels, we obtain predicted labels from the zero-shot model using a single query for each of the 49 randomly sampled images and add them to the prompt. We observe further performance increase on both datasets, with 5.5% on TerraIncognita and 2.7% on UCMerced. The final total accuracy is similar to asking the 50 questions each round, which suggests these three components mostly explain the reason for improved zero-shot performance under a larger query batch size.
4.3 Cost and latency analysis
Many-shot ICL incurs zero additional training cost, but per-query inference can be costly and slow due to long input contexts. To quantitatively measure this, we compute the latency and cost associated with the zero-shot and many-shot requests with and without batching when using Gemini 1.5 Pro on HAM10000 and TerraIncognita. We calculate the costs using the Gemini 1.5 Pro preview pricing ($7 per 1 million input tokens and $21 per 1 million output tokens). For fair comparison and to minimize data transfer artifacts, all requests are sent to the same location where the VM instance is held (“us-central1”). We run the query three times under each setting and report the average.
In the zero-shot regime, we see substantial per-example latency reductions due to query batching, close to a 10x reduction on HAM10000 and 2x on TerraIncognita (Table 3). The per-example cost is similar between the two as there is no additional context needed for including demonstrating examples. In the many-shot regime, we observe substantial reductions in both per-example latency and cost on both datasets. Specifically, for HAM10000, we find a near 35x reduction in latency and 10x reduction in cost, and 20x reduction in latency and 45x reduction in cost for TerraIncognita.
Authors:
(1) Yixing Jiang, Stanford University ([email protected]);
(2) Jeremy Irvin, Stanford University ([email protected]);
(3) Ji Hun Wang, Stanford University ([email protected]);
(4) Muhammad Ahmed Chaudhry, Stanford University ([email protected]);
(5) Jonathan H. Chen, Stanford University ([email protected]);
(6) Andrew Y. Ng, Stanford University ([email protected]).
This paper is