

Table of Links
4 Results and 4.1 Increasing number of demonstrating examples
4.2 Impact of batching queries
A. Prompts used for ICL experiments
C. GPT4(V)-Turbo performance under many-shot ICL
D. Performance of many-shot ICL on medical QA tasks
Acknowledgments and Disclosure of Funding
A Prompts used for ICL experiments
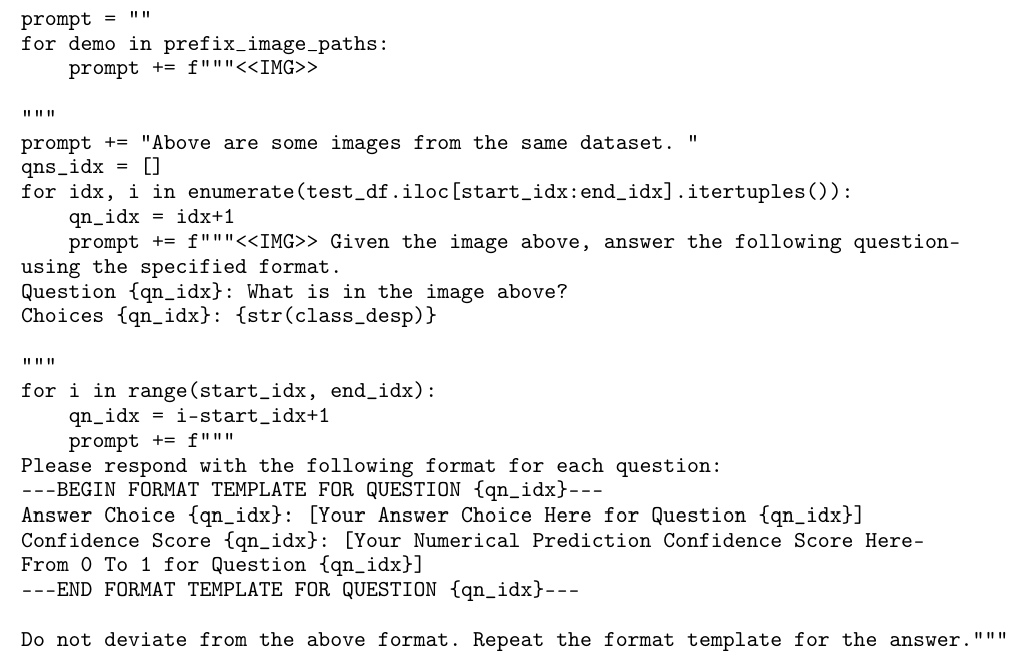
A.1 Prompt used for image classification experiments

A.2 Prompts used for image classification experiments with batching

A.3 Prompts used for batching ablation experiments
A.3.1 Prefixing images
B Prompt selection
We utilize a different set of prompts to test the robustness of ManyICL to differences in prompt wording. We randomly sample two datasets (HAM10000 and EuroSAT) for this experiment due to budget limit.
B.1 Prompts used for prompt selection experiments
Note that only the question section is shown here, and prompt 1 is used for all other image classification experiments.
B.1.1 Prompt 1
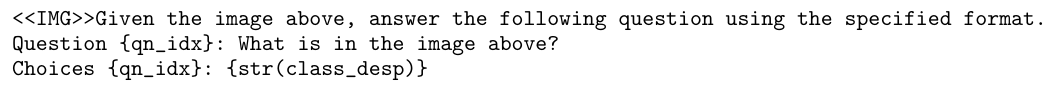
B.1.2 Prompt 2

B.1.3 Prompt 3
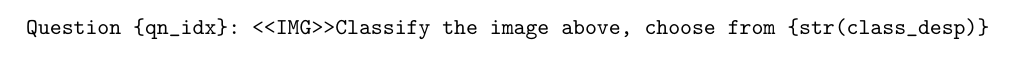

B.2 Prompt selection results
Figure 5 shows the sensitivity of performance to prompt selection on two datasets with three prompts. While there exists a small deviation in performance, but the overall log-linear improvement trend is consistent.
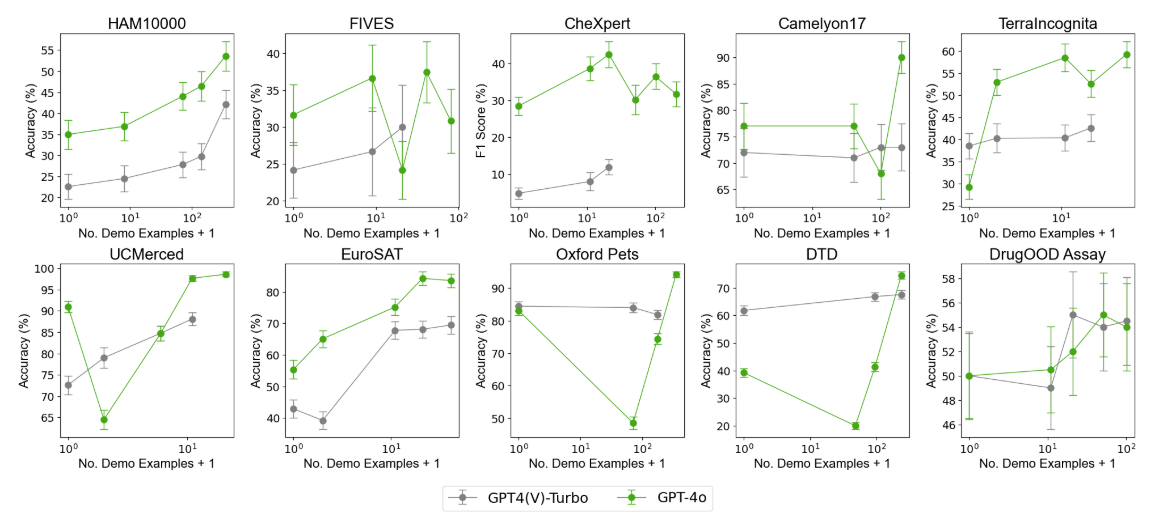
C GPT4(V)-Turbo performance under many-shot ICL
GPT4(V)-Turbo shows mixed results for many-shot ICL, with substantial performance improvements on HAM1000, UCMerced, EuroSAT, and DTD, but minimal improvements or no improvement across the other six datasets (Figure 6). However, we note that we were unable to increase the number of demo examples to the same level as Gemini 1.5 Pro because GPT4(V)-Turbo has a shorter context window and is more prone to timeout errors when scaling. Additionally, GPT4(V)-Turbo seems to generally underperform Gemini 1.5 Pro across the datasets excluding FIVES and EuroSAT for which it seems to mostly match the Gemini 1.5 Pro performance. GPT4(V)-Turbo performance on DrugOOD Assay shows high variance, resembling that of Gemini 1.5 Pro with the peak performance at 40 demo examples.
D Performance of many-shot ICL on medical QA tasks
D.1 Prompt used for medical QA experiments (MedQA, MedMCQA)

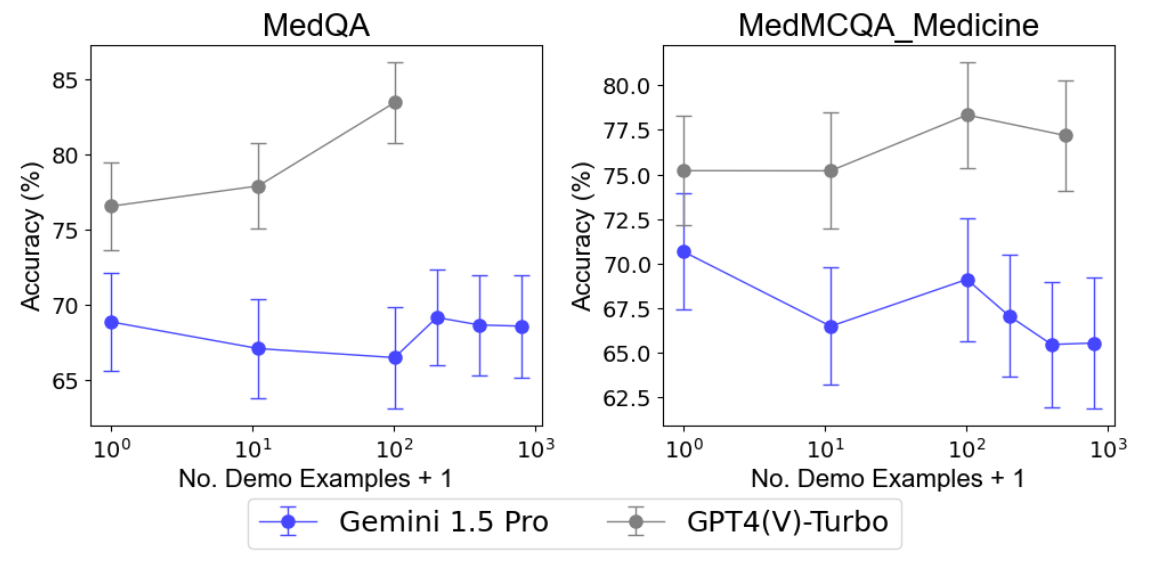

D.2 Results
Figure 7 shows the results on medical QA tasks.
Acknowledgments and Disclosure of Funding
We thank Dr. Jeff Dean, Yuhui Zhang, Dr. Mutallip Anwar, Kefan Dong, Rishi Bommasani, Ravi B. Sojitra, Chen Shani and Annie Chen for their feedback on the ideas and manuscript. Yixing Jiang is supported by National Science Scholarship (PhD). This work is also supported by Google cloud credit. Dr. Jonathan Chen has received research funding support in part by NIH/National Institute of Allergy and Infectious Diseases (1R01AI17812101), NIH/National Institute on Drug Abuse Clinical Trials Network (UG1DA015815 - CTN-0136), Gordon and Betty Moore Foundation (Grant #12409), Stanford Artificial Intelligence in Medicine and Imaging - Human-Centered Artificial Intelligence (AIMI-HAI) Partnership Grant, Google, Inc. Research collaboration Co-I to leverage EHR data to predict a range of clinical outcomes, American Heart Association - Strategically Focused Research Network - Diversity in Clinical Trials and NIH-NCATS-CTSA grant (UL1TR003142) for common research resources.
Authors:
(1) Yixing Jiang, Stanford University ([email protected]);
(2) Jeremy Irvin, Stanford University ([email protected]);
(3) Ji Hun Wang, Stanford University ([email protected]);
(4) Muhammad Ahmed Chaudhry, Stanford University ([email protected]);
(5) Jonathan H. Chen, Stanford University ([email protected]);
(6) Andrew Y. Ng, Stanford University ([email protected]).
This paper is