

Authors:
(1) Yixing Jiang, Stanford University ([email protected]);
(2) Jeremy Irvin, Stanford University ([email protected]);
(3) Ji Hun Wang, Stanford University ([email protected]);
(4) Muhammad Ahmed Chaudhry, Stanford University ([email protected]);
(5) Jonathan H. Chen, Stanford University ([email protected]);
(6) Andrew Y. Ng, Stanford University ([email protected]).
Table of Links
4 Results and 4.1 Increasing number of demonstrating examples
4.2 Impact of batching queries
A. Prompts used for ICL experiments
C. GPT4(V)-Turbo performance under many-shot ICL
D. Performance of many-shot ICL on medical QA tasks
Acknowledgments and Disclosure of Funding
Abstract
Large language models are well-known to be effective at few-shot in-context learning (ICL). Recent advancements in multimodal foundation models have enabled unprecedentedly long context windows, presenting an opportunity to explore their capability to perform ICL with many more demonstrating examples. In this work, we evaluate the performance of multimodal foundation models scaling from few-shot to many-shot ICL. We benchmark GPT-4o and Gemini 1.5 Pro across 10 datasets spanning multiple domains (natural imagery, medical imagery, remote sensing, and molecular imagery) and tasks (multi-class, multi-label, and fine-grained classification). We observe that many-shot ICL, including up to almost 2,000 multimodal demonstrating examples, leads to substantial improvements compared to few-shot (<100 examples) ICL across all of the datasets. Further, Gemini 1.5 Pro performance continues to improve log-linearly up to the maximum number of tested examples on many datasets. Given the high inference costs associated with the long prompts required for many-shot ICL, we also explore the impact of batching multiple queries in a single API call. We show that batching up to 50 queries can lead to performance improvements under zero-shot and many–shot ICL, with substantial gains in the zero-shot setting on multiple datasets, while drastically reducing per-query cost and latency. Finally, we measure ICL data efficiency of the models, or the rate at which the models learn from more demonstrating examples. We find that while GPT-4o and Gemini 1.5 Pro achieve similar zero-shot performance across the datasets, Gemini 1.5 Pro exhibits higher ICL data efficiency than GPT-4o on most datasets. Our results suggest that many-shot ICL could enable users to efficiently adapt multimodal foundation models to new applications and domains. Our codebase is publicly available at https://github.com/stanfordmlgroup/ManyICL.
1 Introduction
Large language models (LLMs) have been shown to substantially benefit from the inclusion of a few demonstrating examples (shots) in the LLM context before the test query [1–3]. This phenomenon, commonly referred to as in-context learning (ICL), enables LLMs to learn from few shots without any updates to model parameters, and therefore improves specialization to new tasks without any further model training. More recently, large multimodal models (LMMs) have also demonstrated the capability of learning from in-context examples [4–6]. Han et al. [5] and Zhang et al. [6] both show that few-shot multimodal ICL specifically helps to improve LMM performance on out-domain or out-of-distribution tasks.
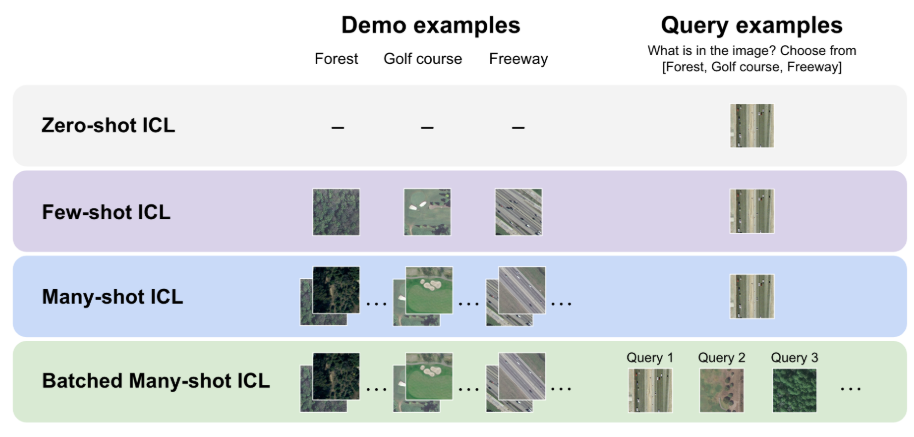
While few-shot ICL has enabled promising performance improvements for both LLMs and LMMs, limited model context windows have constrained research on the impact of increasing the number of demonstrating examples on performance. This is especially true for LMMs as most use a large number of visual tokens to represent images. However, due to recent advancements enabling substantially longer context windows – for example, 128,000 tokens for GPT-4o and up to one million tokens for Gemini 1.5 Pro – it is now possible to explore the effect of drastically increasing the number of demonstrating examples.
To investigate the capability of state-of-the-art multimodal foundation models to perform many-shot ICL, we conduct a large suite of experiments benchmarking model performance on 10 datasets spanning several domains and image classification tasks after scaling up the number of demonstrating examples by multiple orders of magnitude. Specifically, our contributions are as follows:
-
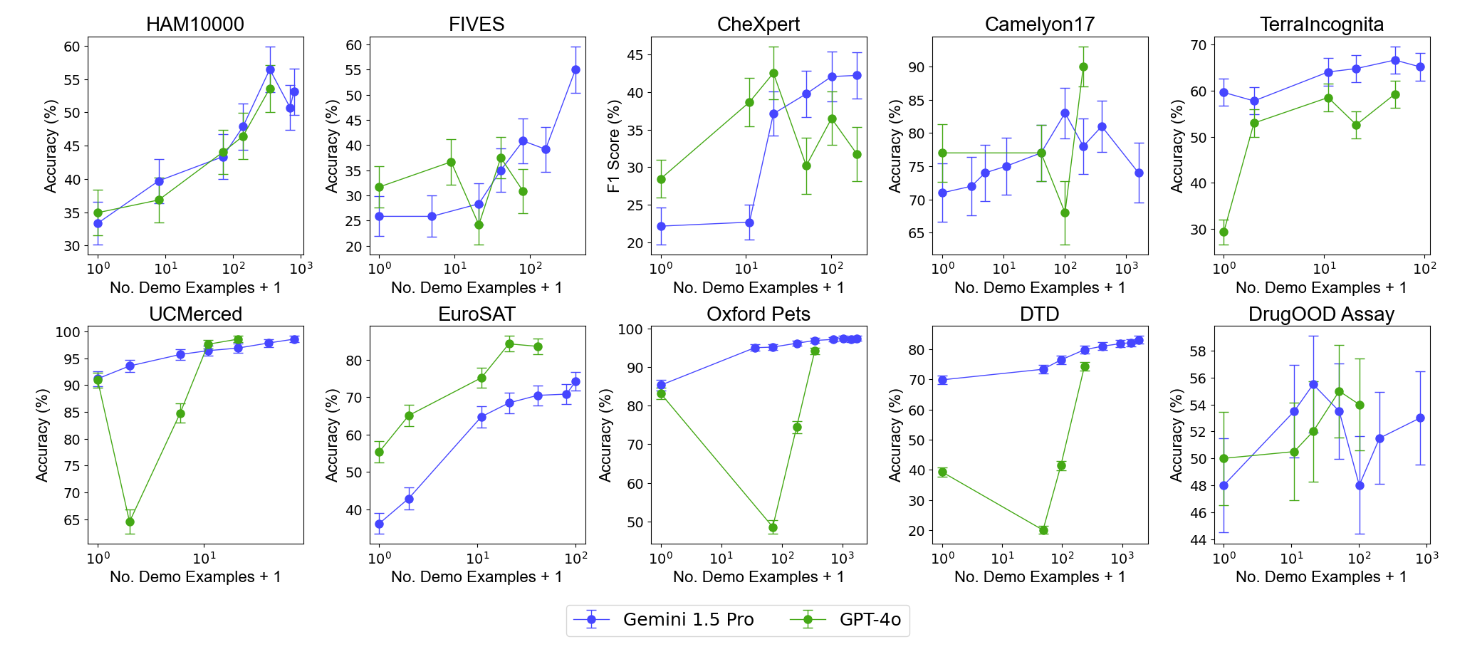
We show that providing multimodal foundation models with many demonstrating examples leads to substantial performance improvements compared to providing only a few demonstrating examples. We observe that the performance of Gemini 1.5 Pro generally improves log-linearly as the number of demonstrating examples increases, whereas GPT-4o exhibits less stable improvements as the number of in-context examples increases.
-
We measure the data efficiency of the models under ICL as the number of demonstrating examples is increased, and find that Gemini 1.5 Pro exhibits higher ICL data efficiency than GPT-4o on most datasets.
-
We demonstrate that batching multiple queries into a single request can achieve similar or better performance than single query requests in a many-shot setting, while enabling substantially lower per-example latency and much cheaper per-example inference cost.
-
We find that batching multiple questions can lead to substantial performance improvements in a zero-shot setting. We design experiments to explain this phenomenon, and find that the improvements are due to a combination of domain calibration, class calibration, and self-generated demonstrating examples due to autoregressive decoding.
Our codebase is publicly available at https://github.com/stanfordmlgroup/ManyICL.
2 Related Work
Scaling ICL. The seminal work of Brown et al. [1] discovered performance improvements for LLMs from increasing the number of in-context examples, but the tested number of demonstrating examples was low (10 to 100), likely due to the restrictive context size (2048 tokens for GPT3). Increasing the number of in-context examples has only been explored recently by a few works [7–9]. Both Li et al. [7] and Agarwal et al. [8] explore scaling in-context learning to more than 1,000 demonstrating examples and find performance improvements across multiple tasks. However, their experiments are limited to text-only benchmarks and do not compare performance across different models.
Multimodal ICL. Due to the recent emergence of LMMs, research on multimodal ICL is still nascent. One prior work developed a new model to leverage complex prompts composed of multimodal inputs in order to allow models to compare images [10], while other recent works explored the generalizability of GPT-4V and Gemini to multimodal out-domain and out-of-distribution tasks, and found that ICL leads to performance benefits for both models across many tasks [6, 5]. However, none of these works have leveraged the new largely expanded context windows to investigate the effects of increasing the number of demonstrating examples.
Batch Querying. Multiple prior works have explored batching queries (also commonly referred to as batch prompting) for more efficient and cheaper inference. Batch prompting was first introduced in Cheng et al. [11], leading to comparable or better performance than single prompting, while achieving substantially reduced inference token cost and latency. Lin et al. [12] observe performance degradation with batched prompts in longer contexts, and propose a variety of techniques to mitigate the performance loss. More recently, additional variations of batch prompting have been proposed, including grouping similar questions together [13], batching prompts of different tasks [14], and concatenating multiple images into a single image collage [15]. We again note that batch prompting with high numbers of demonstrating examples and high numbers of queries has only become feasible due to larger context windows of recent models.
This paper is