

Authors:
(1) An Yan, UC San Diego, [email protected];
(2) Zhengyuan Yang, Microsoft Corporation, [email protected] with equal contributions;
(3) Wanrong Zhu, UC Santa Barbara, [email protected];
(4) Kevin Lin, Microsoft Corporation, [email protected];
(5) Linjie Li, Microsoft Corporation, [email protected];
(6) Jianfeng Wang, Microsoft Corporation, [email protected];
(7) Jianwei Yang, Microsoft Corporation, [email protected];
(8) Yiwu Zhong, University of Wisconsin-Madison, [email protected];
(9) Julian McAuley, UC San Diego, [email protected];
(10) Jianfeng Gao, Microsoft Corporation, [email protected];
(11) Zicheng Liu, Microsoft Corporation, [email protected];
(12) Lijuan Wang, Microsoft Corporation, [email protected].
Editor’s note: This is the part 12 of 13 of a paper evaluating the use of a generative AI to navigate smartphones. You can read the rest of the paper via the table of links below.
Table of Links
- Abstract and 1 Introduction
- 2 Related Work
- 3 MM-Navigator
- 3.1 Problem Formulation and 3.2 Screen Grounding and Navigation via Set of Mark
- 3.3 History Generation via Multimodal Self Summarization
- 4 iOS Screen Navigation Experiment
- 4.1 Experimental Setup
- 4.2 Intended Action Description
- 4.3 Localized Action Execution and 4.4 The Current State with GPT-4V
- 5 Android Screen Navigation Experiment
- 5.1 Experimental Setup
- 5.2 Performance Comparison
- 5.3 Ablation Studies
- 5.4 Error Analysis
- 6 Discussion
- 7 Conclusion and References
6 Discussion
Future benchmarks for device-control. For future benchmarks, more dynamic interaction environments are needed. Even humans can make mistakes sometimes, and in this case, it is important that the evaluation benchmark would allow the model to explore and return to previous status when a mistake is made and realized by the model. It is also interesting to explore how to automatically evaluate success rates for this task, e.g., by using LMMs (Zhang et al., 2023). Another direction is to build GUI navigation datasets with different devices and diverse contents, e.g., personal computers and iPads.
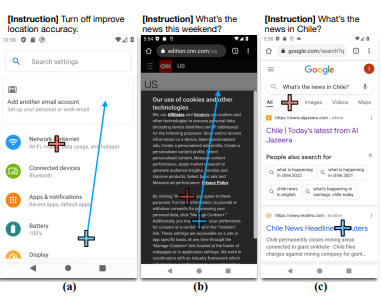
Error correction. A pretrained LMM may make mistakes due to data or algorithm bias. For example, if the agent fails to complete tasks in certain novel settings, how do we correct its errors to avoid mistakes in the future? Moreover, it would be interesting to study this in a continual learning setting, where the agent keeps interacting with new environments and receives new feedback continually.
Model distillation. Using a large-scale model such as GPT-4V for GUI navigation is costly. In the future, it would be interesting to explore model distillation (Polino et al., 2018) for this task, to obtain a much smaller model with competitive navigation performance, which may achieve lower latency and higher efficiency
This paper is available on arxiv under CC BY 4.0 DEED license.