

Authors:
(1) Kexun Zhang, UC Santa Barbara and Equal contribution;
(2) Hongqiao Chen, Northwood High School and Equal contribution;
(3) Lei Li, Carnegie Mellon University;
(4) William Yang Wang,UC Santa Barbara.
Table of Links
- Abstract and Intro
- Related Work
- ToolDec: LLM Tool Use via Finite-State Decoding
- Experiment: ToolDec Eliminates Syntax Errors
- Experiment: ToolDec Enables Generalizable Tool Selection
- Conclusion and References
- Appendix
4. EXPERIMENT I: TOOLDEC ELIMINATES SYNTAX ERRORS
In this section, we show that TOOLDEC can eliminate syntax errors while generating tool calls. We select two recent baselines, ToolLLM and ToolkenGPT, representative of the in-context learning and the fine-tuning paradigm, to showcase TOOLDEC’s ability. Since the tool-use settings for the two baselines are different and cannot be applied to one another, we test TOOLDEC’s performance separately for the two baselines using the benchmarks from the original papers. Through extensive experiments, we show that TOOLDEC can completely eliminate syntactic errors, resulting in better accuracy and shorter inference time.
4.1 BASELINES AND BENCHMARKS
ToolLLM (Qin et al., 2023). ToolLLM is an in-context learning approach to tool-augmented language models. It utilizes an instruction-tuned LLaMA-7B model (Touvron et al., 2023) to use tools. Given the natural language instruction of a tool-dependent task, an API retriever first retrieves a small subset of relevant functions. Textual description and schema of these relevant functions are made available in the context. Then, ToolLLM goes through a multi-step reasoning process using the functions to produce a final answer.
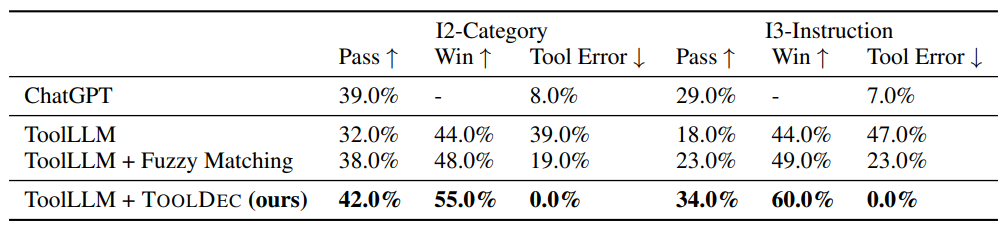
ToolLLM is evaluated on ToolEval, a dataset proposed in the same paper. ToolEval contains tasks that involve a massive set (10,000+) of publicly available REST APIs. We use the most difficult subsets of ToolEval to evaluate our method—I2-Category and I3-Instruction. They contain tasks that need complex and unseen tools from multiple categories (such as geolocation, date/time, and others) to solve. On average, an I2-Category task needs 6.76 tools and an I3-Category task needs 8.24 tools. ToolEval has two main metrics: Pass Rate measures the percentage of tasks for which the model reaches an answer within a certain amount of reasoning steps. Win Rate utilizes an automatic evaluator powered by an LLM following a pre-defined set of criteria for a better path. It compares the quality and correctness of the baseline answers to the reference answer produced by ChatGPT. Qin et al. (2023) finds that the automatic evaluator has a high correlation of 75.8% with human annotators. Other than these two metrics, we also measure Tool Error Rate, the proportion of tasks that have at least one tool-related error.
ToolkenGPT (Hao et al., 2023). ToolkenGPT is a fine-tuning approach to tool use. ToolkenGPT represents each tool as a special token and optimizes only the embedding of the tool tokens for tool use. During inference, ToolkenGPT invokes a tool once the corresponding special token is predicted. During a tool call, it passes arguments by learning from in-context demonstrations. ToolkenGPT uses LLaMA-33B (Touvron et al., 2023) as its base model.

4.2 INTEGRATING TOOLDEC WITH THE BASE MODELS
ToolLLM+TOOLDEC. Following Qin et al. (2023), we use ReAct (Yao et al., 2023) to plan the tool calls of ToolLLM. This conforms to the second case of mode switching in Section 3.2. There are three parts in the FSM for ToolLLM. First, a format FSM that enforces the “Thought, Action, Action Input” syntax of ReAct. After decoding “Action:”, this FSM transitions to the beginning state of the function name FSM, which guarantees that a decoded function name is always valid. We also constructed a JSON-based function argument FSM. We allowed LLMs to reason for 5 steps before it must call the finish action to be considered “pass”.
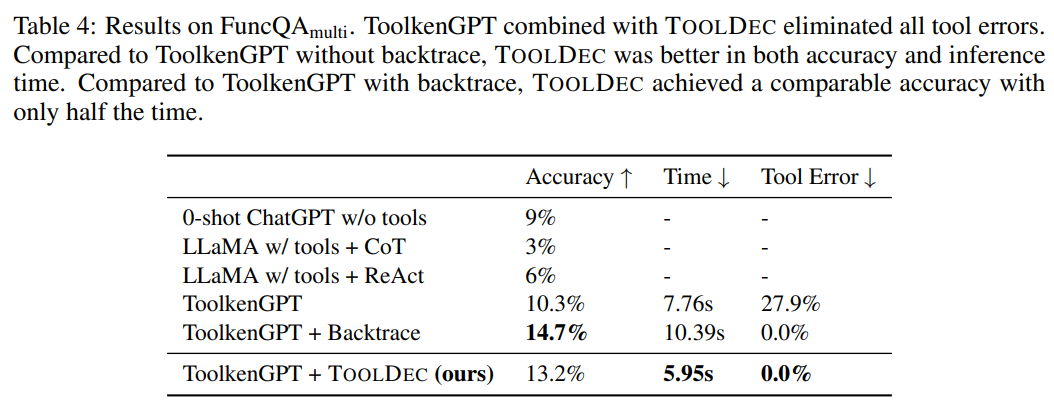
ToolkenGPT+TOOLDEC. Since ToolkenGPT uses special tokens to call tools, TOOLDEC is only applied to guarantee the syntax of arguments. In this experiment, our FSM guarantees that every argument is a valid number, and arguments are separated by commas. It also guarantees that the actual number of arguments passed to a function is exactly the number needed by it. We compared TOOLDEC to two variants of the baseline in Hao et al. (2023), one with backtrace and one without. Backtrace tries to avoid failed tool calls by allowing the LLM to go back and try the next probable token, in place of the failed tool call. To evaluate TOOLDEC, we report the average inference time per problem and tool error rates in addition to accuracy.
4.3 EXPERIMENTAL RESULTS
TOOLDEC enhances in-context learning tool LLMs. Table 3 shows TOOLDEC’s performance on ToolEval. TOOLDEC achieved 55% win rate on I2-Category and 60% win rate on I3-instruction. As a drop-in replacement of the original decoding algorithm, TOOLDEC eliminated all three types of tool-related errors and achieved the best win rate and pass rate, even beating ChatGPT.
The high tool error rate of the baselines suggests that even after instruction finetuning, ToolLLM still lacks the ability of accurately invoke external tools from the tool documentation. This inability is more exposed when there is a large variety of tools available, as in I3-Instruction. Furthermore, these errors significantly impacted the model’s ability to complete tasks.
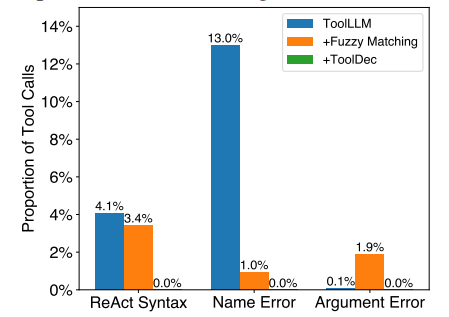
We present the error rates of each error type on two benchmarks in Figure 4. For ToolLLMs, name error, i.e. calling a non-existent tool, was the most common syntactic error in a tool call. TOOLDEC completely eliminated all three errors.
With function name hallucination being the most prevalent tool-related error, a slightly better baseline was to mitigate it with fuzzy matching by suffix. We present the results of the baseline with fuzzy matching as ToolLLM + Fuzzy Matching, and without as ToolLLM. This mitigation increased pass rate but had little impact on win rate, as evident in Table 3, because wrong APIs could often be chosen when a model was unable to precisely call the tool it wanted. Overall, our experiments on ToolLLM demonstrate that TOOLDEC is highly effective on in-context learning LLMs. Through the next baseline, ToolkenGPT, we show that TOOLDEC is also beneficial to fine-tuned tool LLMs.
TOOLDEC enhances fine-tuning tool LLMs. Table 4 shows the results on FuncQAmulti. Although ToolkenGPT eliminates the possibility of calling non-existent tool names by fine-tuning a special token embedding, it can still suffer from other syntactic errors, which is demonstrated by the 27.9% tool error rate. As a drop-in replacement, TOOLDEC increased ToolkenGPT’s accuracy while being much faster in inference. Although ToolkenGPT + backtrace achieved slightly better accuracy than TOOLDEC, it used 2x more time to try different tools. Note that since TOOLDEC eliminated all tool errors, there were no failed tool calls for backtrace to retry. The results underscore tool-related errors’ relevancy and TOOLDEC’s applicability to both recent in-context learning and fine-tuning tool-augmented LLMs.
This paper is available on arxiv under CC 4.0 DEED license.