
Authors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]).
Table of Links
2 COCOGEN: Representing Commonsense structures with code and 2.1 Converting (T,G) into Python code
2.2 Few-shot prompting for generating G
3 Evaluation and 3.1 Experimental setup
3.2 Script generation: PROSCRIPT
3.3 Entity state tracking: PROPARA
3.4 Argument graph generation: EXPLAGRAPHS
6 Conclusion, Acknowledgments, Limitations, and References
A Few-shot models size estimates
G Designing Python class for a structured task
Abstract
We address the general task of structured commonsense reasoning: given a natural language input, the goal is to generate a graph such as an event or a reasoning-graph. To employ large language models (LMs) for this task, existing approaches “serialize” the output graph as a flat list of nodes and edges. Although feasible, these serialized graphs strongly deviate from the natural language corpora that LMs were pre-trained on, hindering LMs from generating them correctly. In this paper, we show that when we instead frame structured commonsense reasoning tasks as code generation tasks, pre-trained LMs of code are better structured commonsense reasoners than LMs of natural language, even when the downstream task does not involve source code at all. We demonstrate our approach across three diverse structured commonsense reasoning tasks. In all these natural language tasks, we show that using our approach, a code generation LM (CODEX) outperforms natural-LMs that are fine-tuned on the target task (e.g., T5) and other strong LMs such as GPT-3 in the fewshot setting. Our code and data are available at https://github.com/madaan/CoCoGen.
1 Introduction
The growing capabilities of large pre-trained language models (LLMs) for generating text have enabled their successful application in a variety of tasks, including summarization, translation, and question-answering (Wang et al., 2019; Raffel et al., 2019; Brown et al., 2020; Chowdhery et al., 2022).
Nevertheless, while employing LLMs for natural language (NL) tasks is straightforward, a major remaining challenge is how to leverage LLMs for structured commonsense reasoning, including tasks such as generating event graphs (Tandon et al., 2019), reasoning graphs (Madaan et al., 2021a), scripts (Sakaguchi et al., 2021), and argument explanation graphs (Saha et al., 2021). Unlike traditional commonsense reasoning tasks such as reading comprehension or question answering, structured commonsense aims to generate structured output given a natural language input. This family of tasks relies on the natural language knowledge learned by the LLM, but it also requires complex structured prediction and generation.
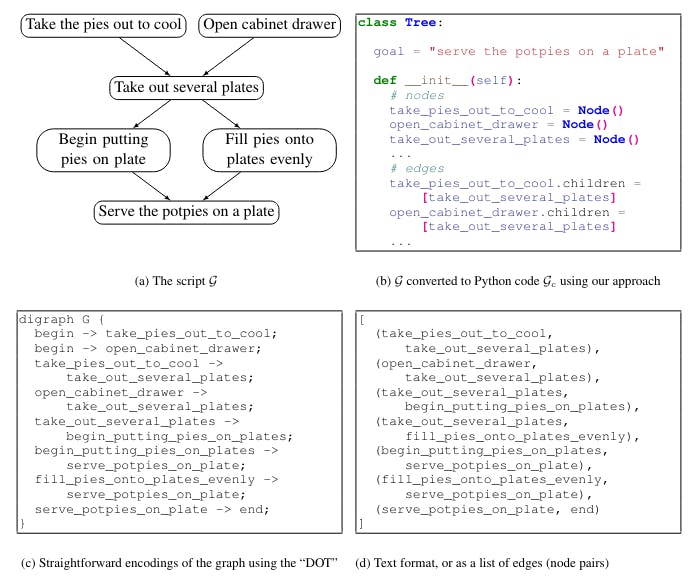
To leverage LLMs, existing structured commonsense generation models modify the output format of a problem. Specifically, the structure to be generated (e.g., a graph or a table) is converted, or “serialized”, into text. Such conversions include “flattening” the graph into a list of node pairs (Figure 1d), or into a specification language such as DOT (Figure 1c; Gansner et al., 2006).
While converting the structured output into text has shown promising results (Rajagopal et al., 2021; Madaan and Yang, 2021), LLMs struggle to generate these “unnatural” outputs: LMs are primarily pre-trained on free-form text, and these serialized structured outputs strongly diverge from the majority of the pre-training data. Further, for natural language, semantically relevant words are typically found within a small span, whereas neighboring nodes in a graph might be pushed farther apart when representing a graph as a flat string.
Thus, a language model which was trained on natural language text is likely to fail to capture the topology of the graph. Consequently, using LLMs for graph generation typically requires a large amount of task-specific training data, and their generated outputs show structural errors and semantic inconsistencies, which need to be further fixed either manually or by using a secondary downstream model (Madaan et al., 2021b).
Despite these struggles, the recent success of large-language models of code (Code-LLMs; Chen et al., 2021b; Xu et al., 2022) for tasks such as code generation from natural language (Austin et al., 2021; Nijkamp et al., 2022), code completion (Fried et al., 2022), and code translation (Wang et al., 2021), show that Code-LLMs are able to perform complex reasoning on structured data such as programs. Thus, instead of forcing LLMs of natural language (NL-LLMs) to be fine-tuned on structured commonsense data, an easier way to close the discrepancy between the pre-training data (free-form text) and the task-specific data (commonsense reasoning graphs) is to adapt LLMs that were pre-trained on code to structured commonsense reasoning in natural language.
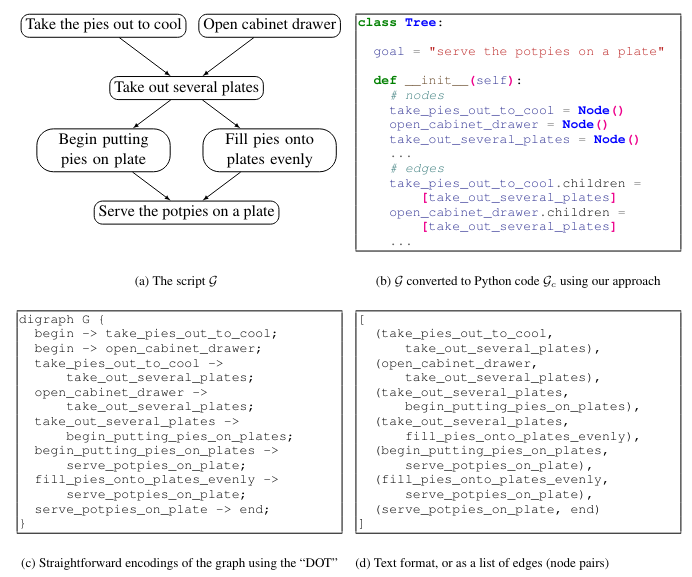
Thus, our main insight is that large language models of code are good structured commonsense reasoners. Further, we show that Code-LLMs can be even better structured reasoners than NL-LLMs, when converting the desired output graph into a format similar to that observed in the code pre-training data. We call our method COCOGEN: models of Code for Commonsense Generation, and it is demonstrated in Figure 1.
Our contributions are as follows:
-
We highlight the insight that Code-LLMs are better structured commonsense reasoners than NL-LLMs, when representing the desired graph prediction as code.
-
We propose COCOGEN: a method for leveraging LLMs of code for structured commonsense generation.
-
We perform an extensive evaluation across three structured commonsense generation tasks and demonstrate that COCOGEN vastly outperforms NL-LLMs, either fine-tuned or few-shot tested, while controlling for the number of downstream task examples.
-
We perform a thorough ablation study, which shows the role of data formatting, model size, and the number of few-shot examples.
This paper is available on arxiv under CC BY 4.0 DEED license.