

Authors:
(1) Michael Moor, Department of Computer Science, Stanford University, Stanford, USA and these authors contributed equally to this work;
(2) Qian Huang, Department of Computer Science, Stanford University, Stanford, USA and these authors contributed equally to this work;
(3) Shirley Wu, Department of Computer Science, Stanford University, Stanford, USA;
(4) Michihiro Yasunaga, Department of Computer Science, Stanford University, Stanford, USA;
(5) Cyril Zakka, Department of Cardiothoracic Surgery, Stanford Medicine, Stanford, USA;
(6) Yash Dalmia, Department of Computer Science, Stanford University, Stanford, USA;
(7) Eduardo Pontes Reis, Hospital Israelita Albert Einstein, Sao Paulo, Brazil;
(8) Pranav Rajpurkar, Department of Biomedical Informatics, Harvard Medical School, Boston, USA;
(9) Jure Leskovec, Department of Computer Science, Stanford University, Stanford, USA.
Table of Links
6 Discussion, Acknowledgments, and References
A APPENDIX
A.1 ADDITIONAL DETAILS FOR MTB DATASET
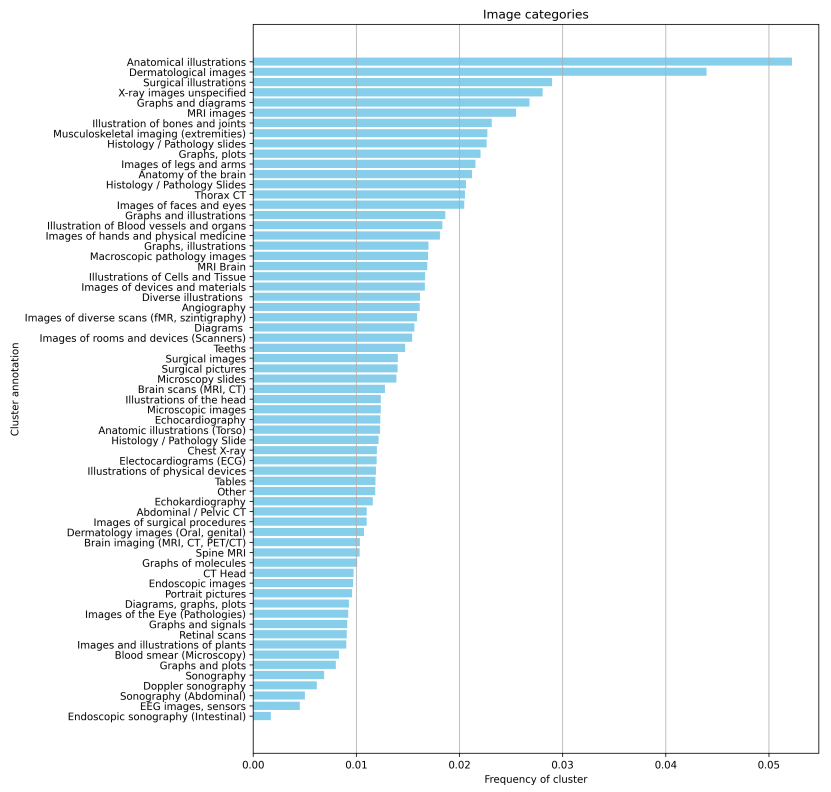
Clustering the images In a post-hoc analysis, we clustered the image embeddings of the MTB dataset into a large number of clusters (100) and manually reviewed examples of each cluster to assign an annotation. We discard noisy or unclear clusters and display the remaining clusters and their frequency in Figure 7.
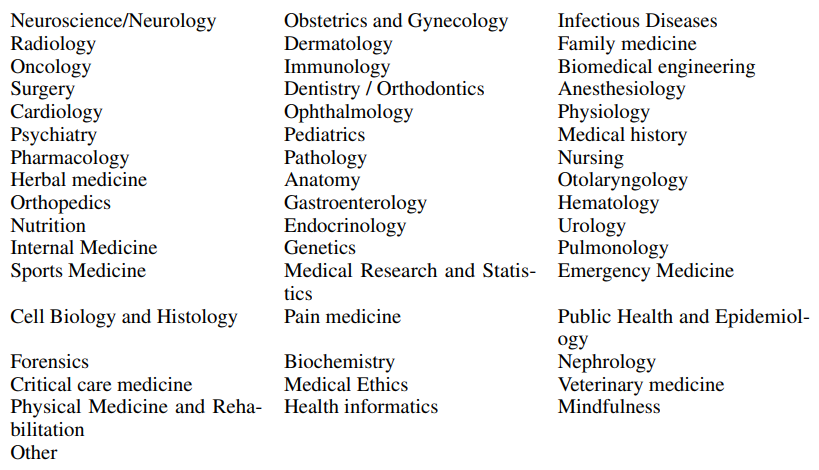
Classification of book titles Here, we provide further details about the creation of Figure 3. Table 4 lists the categories used to prompt the Claude-1 model to classify each book title. We initially prompted with 3 more very rare categories (Geriatrics, Occupational medicine, Space medicine), but merge them into the ”Other” group for visualization purposes.
A.2 ADDITIONAL DETAILS FOR VISUAL USMLE DATASET

This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.