

Table of Links
2 COCOGEN: Representing Commonsense structures with code and 2.1 Converting (T,G) into Python code
2.2 Few-shot prompting for generating G
3 Evaluation and 3.1 Experimental setup
3.2 Script generation: PROSCRIPT
3.3 Entity state tracking: PROPARA
3.4 Argument graph generation: EXPLAGRAPHS
6 Conclusion, Acknowledgments, Limitations, and References
A Few-shot models size estimates
G Designing Python class for a structured task
3 Evaluation
We experiment with three diverse structured commonsense generation tasks: (i) script generation (PROSCRIPT, Section 3.2), (ii) entity state tracking (PROPARA, Section 3.3), and (iii) explanation graph generation (EXPLAGRAPHS, Section 3.4) Dataset details are included in Appendix D. Despite sharing the general goal of structured commonsense generation, the three tasks are quite diverse in terms of the generated output and the kind of required reasoning.
3.1 Experimental setup
Model As our main Code-LLM for COCOGEN, we experiment with the latest version of CODEX code-davinci-002 from OpenAI[1] in few-shot prompting mode.
Baselines We experimented with the following types of baselines:
-
Text few-shot: Our hypothesis is that codegeneration models can be repurposed to generate structured output better. Thus, natural baselines for our approach are NL-LLMs – language models trained on natural language corpus. We experiment with the latest versions of CURIE (text-curie-001) and DAVINCI (text-davinci-002), the two GPT-3 based models by OpenAI (Brown et al., 2020). For both these models, the prompt consists of (T , G) examples, where G is simply flattened into a string (as in Figure 1c). DAVINCI is estimated to be much larger in size than CURIE, as our experiments also reveal (Appendix A). DAVINCI, popularly known as GPT-3, is the strongest text generation model available through OpenAI APIs.[2]
-
Fine-tuning: we fine-tune a T5-large model for EXPLAGRAPHS, and use the results from Sakaguchi et al. (2021) on T5-xxl for PROSCRIPT tasks. In contrast to the few-shot setup where the model only has access to a few examples, fine-tuned models observe the entire training data of the downstream task.
Choice of prompt We created the prompt p by randomly sampling k examples from the training set. As all models have a bounded input size (e.g., 4096 tokens for CODEX code-davinci-002 and 4000 for GPT-3 text-davinci-002), the exact value of k is task dependent: more examples can fit in a prompt in tasks where (T , G) is short. In our experiments, k varies between 5 and 30, and the GPT-3 baseline is always fairly given the same prompts as CODEX. To control for the variance caused by the specific examples selected into p, we repeat each experiment with at least 3 different prompts, and report the average. We report the mean and standard deviations in Appendix I.
COCOGEN: We use COCOGEN to refer to setups where a CODEX is used with a Python prompt. In Section 4, we also experiment with dynamically creating a prompt for each input example, using a NL-LLMs with code prompts, and using CodeLLMs with textual prompts.
3.2 Script generation: PROSCRIPT
Given a high-level goal (e.g., bake a cake), the goal of script generation is to generate a graph where each node is an action, and edges capture dependency between the actions (Figure 1a). We use the PROSCRIPT (Sakaguchi et al., 2021) dataset, where the scripts are directed acyclic graphs, which were collected from a diverse range of sources including ROCStories (Mostafazadeh et al., 2016), Descript (Wanzare et al., 2016), and Virtual home (Puig et al., 2018).

Figure 1 shows an input-output example from PROSCRIPT, and our conversion of the graph into Python code: we convert each node v ∈ V into an instance of a Node class; we create the edges by adding children attribute for each of the nodes. Additional examples are present in Figure 6
To represent a sample for edge prediction, we list the nodes in a random order (specified after the comment # nodes in Figure 1b). The model then
completes the class by generating the code below the comment # edges.

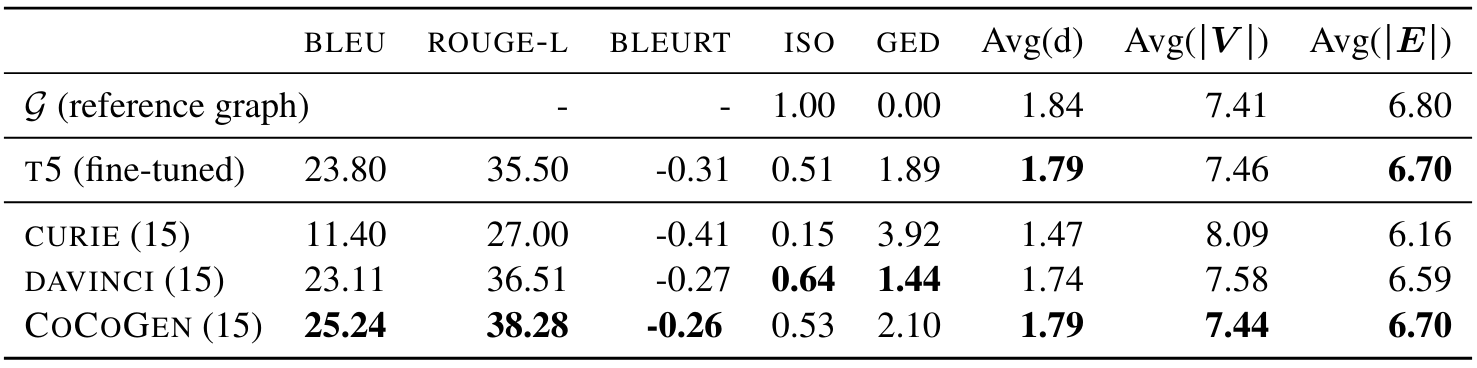
Results Table 1 shows the results for script generation. The main results are that COCOGEN (based on CODEX), with just 15 prompt examples, outperforms the fine-tuned model T5 which has been finetuned on all 3500 samples. Further, COCOGEN outperforms the few-shot NL-LM CURIE across all semantic metrics and structural metrics. COCOGEN outperforms DAVINCI across all semantic metrics, while DAVINCI performs slightly better in two structural metrics.
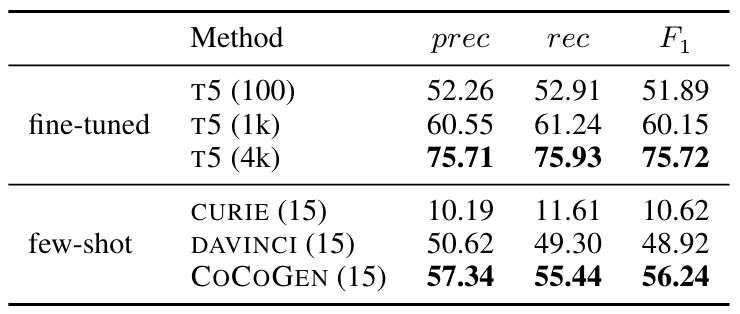
Table 2 shows the results for edge prediction: COCOGEN significantly outperforms the NLLLMs CURIE and DAVINCI. When comparing with T5, which was fine-tuned, COCOGEN with only 15 examples outperforms the fine-tuned T5 which was fine-tuned on 100 examples. The impressive performance in the edge-generation task allows us to highlight the better ability of COCOGEN in capturing structure, while factoring out all models’ ability to generate the NL content.
This paper is available on arxiv under CC BY 4.0 DEED license.
[1] As of June 2022
[2] https://beta.openai.com/docs/models/gpt-3
Authors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]).