
Authors:
(1) Sebastian Dziadzio, University of Tübingen ([email protected]);
(2) Çagatay Yıldız, University of Tübingen;
(3) Gido M. van de Ven, KU Leuven;
(4) Tomasz Trzcinski, IDEAS NCBR, Warsaw University of Technology, Tooploox;
(5) Tinne Tuytelaars, KU Leuven;
(6) Matthias Bethge, University of Tübingen.
Table of Links
2. Two problems with the current approach to class-incremental continual learning
3. Methods and 3.1. Infinite dSprites
4. Related work
4.1. Continual learning and 4.2. Benchmarking continual learning
5.1. Regularization methods and 5.2. Replay-based methods
5.4. One-shot generalization and 5.5. Open-set classification
Conclusion, Acknowledgments and References
Abstract
The ability of machine learning systems to learn continually is hindered by catastrophic forgetting, the tendency of neural networks to overwrite existing knowledge when learning a new task. Existing continual learning methods alleviate this problem through regularisation, parameter isolation, or rehearsal, and are typically evaluated on benchmarks consisting of a handful of tasks. We propose a novel conceptual approach to continual classification that aims to disentangle class-specific information that needs to be memorized from the class-agnostic knowledge that encapsulates generalization. We store the former in a buffer that can be easily pruned or updated when new categories arrive, while the latter is represented with a neural network that generalizes across tasks. We show that the class-agnostic network does not suffer from catastrophic forgetting and by leveraging it to perform classification, we improve accuracy on past tasks over time. In addition, our approach supports open-set classification and one-shot generalization. To test our conceptual framework, we introduce Infinite dSprites, a tool for creating continual classification and disentanglement benchmarks of arbitrary length with full control over generative factors. We show that over a sufficiently long time horizon all major types of continual learning methods break down, while our approach enables continual learning over hundreds of tasks with explicit control over memorization and forgetting.
1. Introduction
A machine learning system designed for continual learning must not only adapt to the current task, but also improve its performance on past tasks and build representations that facilitate the learning of future tasks. The latter two requirements are known as backward and forward transfer. The path to meeting these requirements is obstructed by catastrophic forgetting, the inability to preserve existing knowledge upon learning new information.
As noted in early studies [24], catastrophic forgetting is caused by destructive model updates, where adjustments to model parameters, made through gradient descent, focus solely on the current task’s objective and can potentially impair performance on past tasks. To mitigate this issue, continual learning methods employ strategies such as (i) regularization, which aims to preserve existing knowledge by limiting the plasticity of selected network weights [15, 17, 26, 36], (ii) parameter isolation or dynamic architectures, which effectively solve each task with a dedicated model [6, 33], or (iii) replay, which augments the training data with stored samples from past tasks [4, 12, 30, 32].
Most continual learning methods are evaluated on image classification benchmarks in which a discriminative model is transferred across tasks that typically involve disjoint sets of classes. We argue that this purely discriminative learning framework is not conducive to positive forward or backward transfer. Supervised classification networks tend to preserve only the features that are relevant for predicting the output labels in the training data [11, 35]. In a continual learning setting, these features transfer poorly to future tasks with a completely different set of labels. Conversely, gradient updates with respect to current task’s objective do not encourage preserving features relevant to previous tasks.
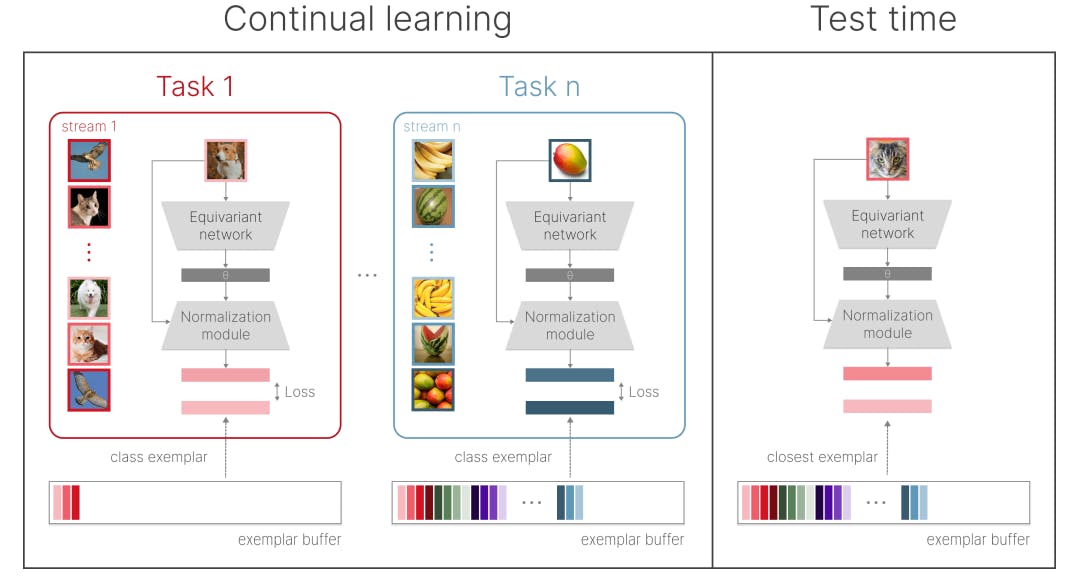
Based on these observations, we propose an alternative paradigm for continual learning centered around the idea of transferring modules that learn the general aspects of the problem (for example identity-preserving transforms that act similarly on all objects, such as illumination changes). We hypothesize that destructive model updates can be avoided by separating two objectives: (i) generalization, or learning class-agnostic transforms that successfully transfer to past and future tasks, and (ii) memorization of class-specific information. Crucially, our framework resolves the catastrophic forgetting issue by disentangled learning, that is, having a separate update procedure for the generalization model and the memory buffer (please note the difference from learning disentangled representations). This separation allows us to maintain, prune, and expand task-specific knowledge stored in the memory buffer while continuously training the generalization model. By focusing on learning the universal transformations, we can not only avoid destructive gradient updates, but efficiently accumulate knowledge over time.
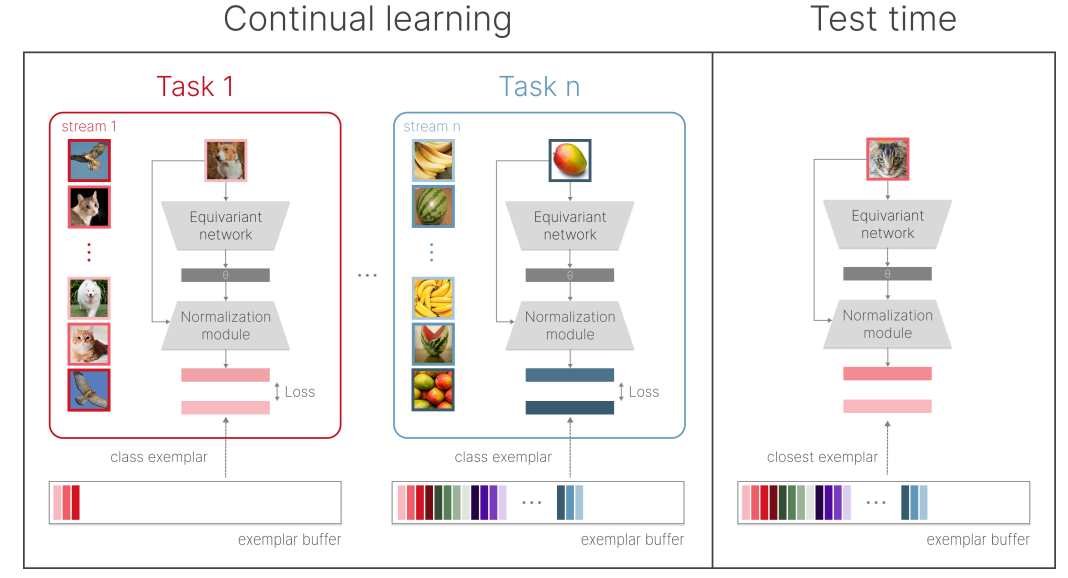
To demonstrate our proposed idea of learning universal transformations, we introduce infinite dSprites (idSprites), a continual learning benchmark generator inspired by the dSprites dataset [23]. It allows for procedurally generating a virtually infinite progression of random two-dimensional shapes. Similar to [23], we generate each unique shape in every combination of orientation, scale, and position (see Fig. 2). Most importantly, by providing the ground truth values of individual factors of variation (FoVs), idSprites enables us to learn general transformations, thereby separating generalization from memorization and testing our main hypothesis. We hope that by releasing idSprites as a Python package we will encourage the research community to test their methods on our benchmark.
Section 3.2 describes an implementation of our disentangled learning framework in the context of class-incremental continual learning. Our proof of concept consists of an equivariant network that learns to regress the parameters of an affine transform that maps any input into its canonical form, a normalisation module that applies the predicted affine transformation to the input, and an exemplar buffer that stores a single exemplar per class. Figure 1 shows the main components of our framework.
Contributions We summarize the most important contributions of this work below:
• We introduce a new framework for generating continual classification and disentanglement benchmarks that for the first time allows testing continual learning methods over thousands of tasks. We will open-source our software package upon acceptance.
• We propose a novel continual learning paradigm based on learning symmetry transformations, which circumvents catastrophic forgetting by separating gradient-based model updates from explicit memory edits.
• We demonstrate that as the number of tasks grows, regularization-based continual learning methods quickly break down and replay-based methods either deteriorate in performance or become impractical due to extensive use of memory and compute.
• We show that our approach exhibits significant forward and backward transfer, strong open-set classification performance, and excellent zero-shot generalisation. It can learn over hundreds of tasks with a constant computational budget and a slowly growing memory footprint.
This paper is available on arxiv under CC 4.0 license.