

Authors:
(1) An Yan, UC San Diego, [email protected];
(2) Zhengyuan Yang, Microsoft Corporation, [email protected] with equal contributions;
(3) Wanrong Zhu, UC Santa Barbara, [email protected];
(4) Kevin Lin, Microsoft Corporation, [email protected];
(5) Linjie Li, Microsoft Corporation, [email protected];
(6) Jianfeng Wang, Microsoft Corporation, [email protected];
(7) Jianwei Yang, Microsoft Corporation, [email protected];
(8) Yiwu Zhong, University of Wisconsin-Madison, [email protected];
(9) Julian McAuley, UC San Diego, [email protected];
(10) Jianfeng Gao, Microsoft Corporation, [email protected];
(11) Zicheng Liu, Microsoft Corporation, [email protected];
(12) Lijuan Wang, Microsoft Corporation, [email protected].
Editor’s note: This is the part 5 of 13 of a paper evaluating the use of a generative AI to navigate smartphones. You can read the rest of the paper via the table of links below.
Table of Links
- Abstract and 1 Introduction
- 2 Related Work
- 3 MM-Navigator
- 3.1 Problem Formulation and 3.2 Screen Grounding and Navigation via Set of Mark
- 3.3 History Generation via Multimodal Self Summarization
- 4 iOS Screen Navigation Experiment
- 4.1 Experimental Setup
- 4.2 Intended Action Description
- 4.3 Localized Action Execution and 4.4 The Current State with GPT-4V
- 5 Android Screen Navigation Experiment
- 5.1 Experimental Setup
- 5.2 Performance Comparison
- 5.3 Ablation Studies
- 5.4 Error Analysis
- 6 Discussion
- 7 Conclusion and References
4 iOS Screen Navigation Experiment
4.1 Experimental Setup
Dataset We begin by conducting analytical experiments on iOS screens to understand GPT-4V’s capability in GUI navigation. Successfully operating smartphones in a human-like manner involves different types of screen understanding abilities. Firstly, there is the semantic reasoning ability, which involves comprehending screen inputs and articulating the necessary actions to fulfill given instructions. Secondly, there is the need to translate these action descriptions into specific localized actions, such as determining the precise location for a screen click. Correspondingly, we develop two sets of test screens to disentangle these two aspects, which are referred to as “intended action description” and “localized action execution,” respectively.
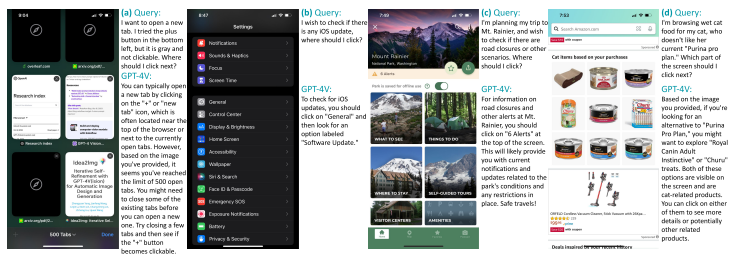
In this study, we gather 110 instructions from 6 human annotators, evenly divided into two distinct sets, containing iOS screens with and without added marks. The first set, “intended action description,” involves GPT-4V taking an iOS screenshot image and an instruction as inputs, and generating an open-ended text description of the desired action to perform. This set aims to assess GPT-4V’s ability to reason the correct action to perform. Moving beyond having someone click the screen for GPT4V (Yang et al., 2023c; Lin et al., 2023), we investigate directly generating formatted executable actions. In the second set, “localized action execution,” we add marks (Yang et al., 2023b) to ground screen locations with interactive SAM (Kirillov et al., 2023), and let GPT-4V use the mark indexes to perform localized actions. Other approaches, such as textualized box coordinates (Chen et al., 2022; Yang et al., 2022; Wang et al., 2022b), screen visual grounding (Yu et al., 2016; Mao et al., 2016; Plummer et al., 2015; Yang et al., 2019; Deng et al., 2021), object detectors (Ren et al., 2015; Carion et al., 2020) could also translate action descriptions into executable actions.
Human evaluation metrics. We use human evaluation for the analytical experiments on iOS screens, with a binary score for each sample indicating if the output is correct. For “intended action description”, human annotators determine if the output text description could lead to the correct output. For “localized action execution,” human annotators assess if clicking the location (i.e., location of the selected mark) fulfills the given instruction. Each sample is assigned a binary score, either 0 or 1, to reflect its correctness.
This paper is available on arxiv under CC BY 4.0 DEED license.